
Künstliche Intelligenz in GREYHOUND
Ob beim Übersetzen von Texten, der Erkennung von Absichten, der Datenklassifizierung oder dem Formulieren passender Antworten: So genannte “künstliche Intelligenz” kann heute bereits an vielen Stellen im Arbeitsalltag helfen. Ab Version 5.5.276 build 3890 verfügt GREYHOUND über ein optionales AI Pack bestehend aus AI Agent + AI Human Assist. In diesem Artikel ist beschrieben, was nötig ist, um KI in GREYHOUND zu nutzen, wie sie konfiguriert wird und wie KI im Arbeitsalltag hilft.
AI Pack: Was kann KI in GREYHOUND?
“Kann ich vollautomatisch meine gesamten Mails beantworten lassen, sodass mein Posteingang immer leer ist?” Ja, das ginge.
- Der AI Agent macht es möglich. Er lässt sich für die Erstellung automatischer Antworten auf Standardanfragen nutzen.
- Und für die händische Bearbeitung von Anfragen gibt einem der AI Human Assist leistungsstarke KI-Textwerkzeuge an die Hand, für eine effizientere Bearbeitung von Kundenanfragen.
KI in GREYHOUND einrichten
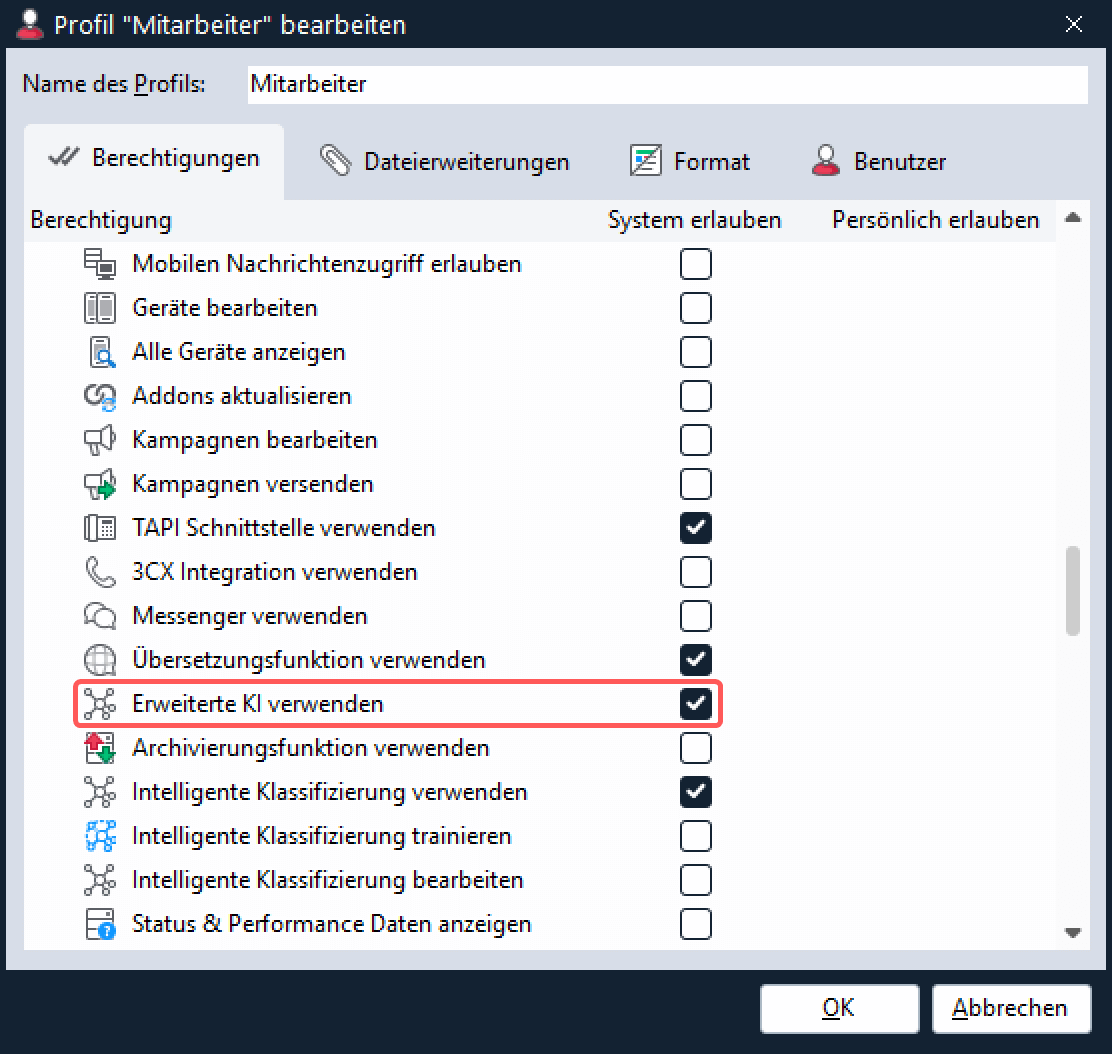
Für alle Benutzer, die automatische Textvorschläge von der KI generieren können sollen, ist unter Einstellungen > Profile das Recht “Erweiterte KI verwenden” zu setzen:
Die nötigen Themen für die Nutzung von KI Agenten werden automatisch angelegt. Sie lauten:

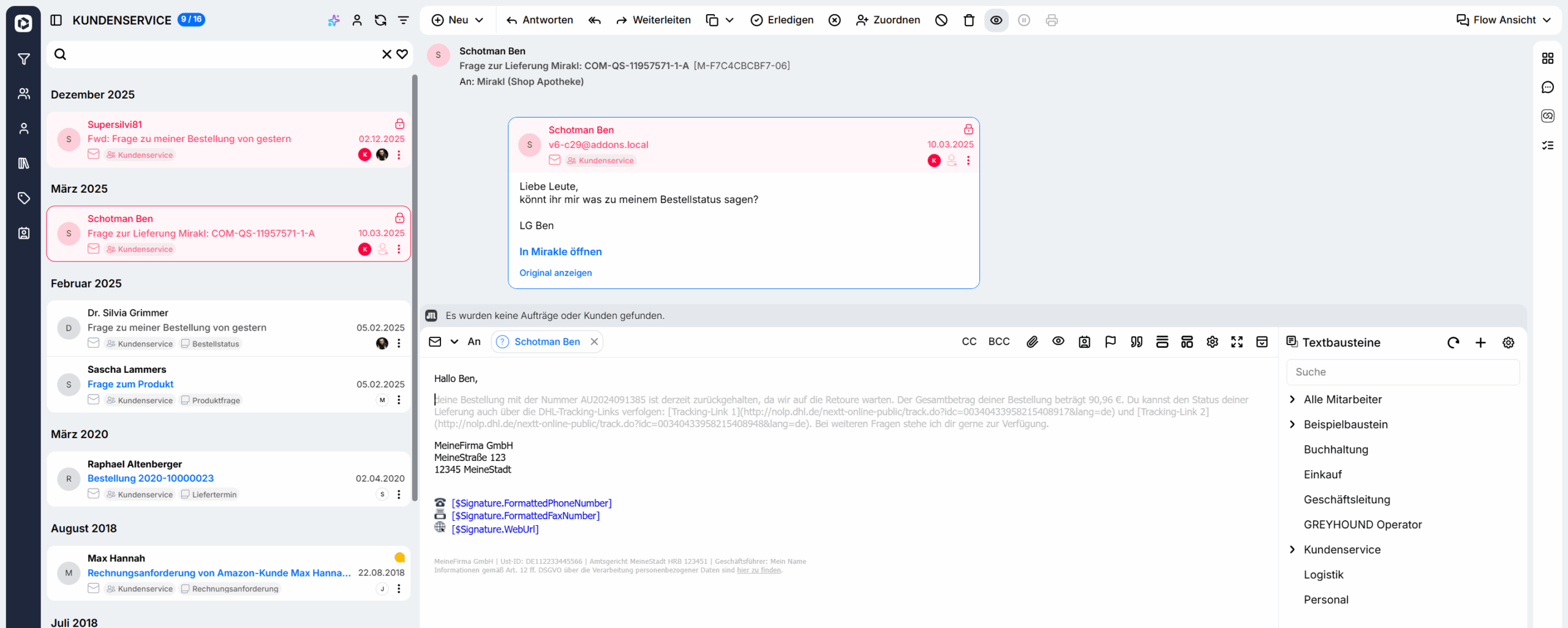
KI nutzen: AI Human Assist
Sobald alle oben genannten Punkte erfüllt sind, kann die KI in GREYHOUND genutzt werden. Der AI Human Assist steht zur Verfügung im Windows Client und im Webclient. Die Kernfunktionen kompakt in 1.5 Minuten:
Fertige Antworten generieren (Autovervollständigung)
Ist man in der Mail-Beantwortung und wartet ein paar Sekunden, generiert die KI automatisch einen Antwortvorschlag, der sich mit Enter einfügen lässt.
Diese Autovervollständigung beim Tippen steht nur im Webclient zur Verfügung. Im Windows Client gibt es stattdessen die Funktion “Antwortvorschlag generieren lassen”.
Im Windows Client steckt “die Magie” in folgendem Button:

Anstatt sich die Finger wund zu tippen kann man sich via KI in Sekundenschnelle über den KI-Antwortvorschlag einen passenden Mail-Text KI-gestützt generieren lassen. Einfach einen kurzen Textkontext eintippen, diesen markieren, auf den Button “Erstelle Antwortvorschlag” klicken und die KI analysiert den gesamten bisherige Mail-Verlauf und erstellt einen passenden Antwortvorschlag:
Step 1 – die Anfrage:

Step 2 – der Kontext:
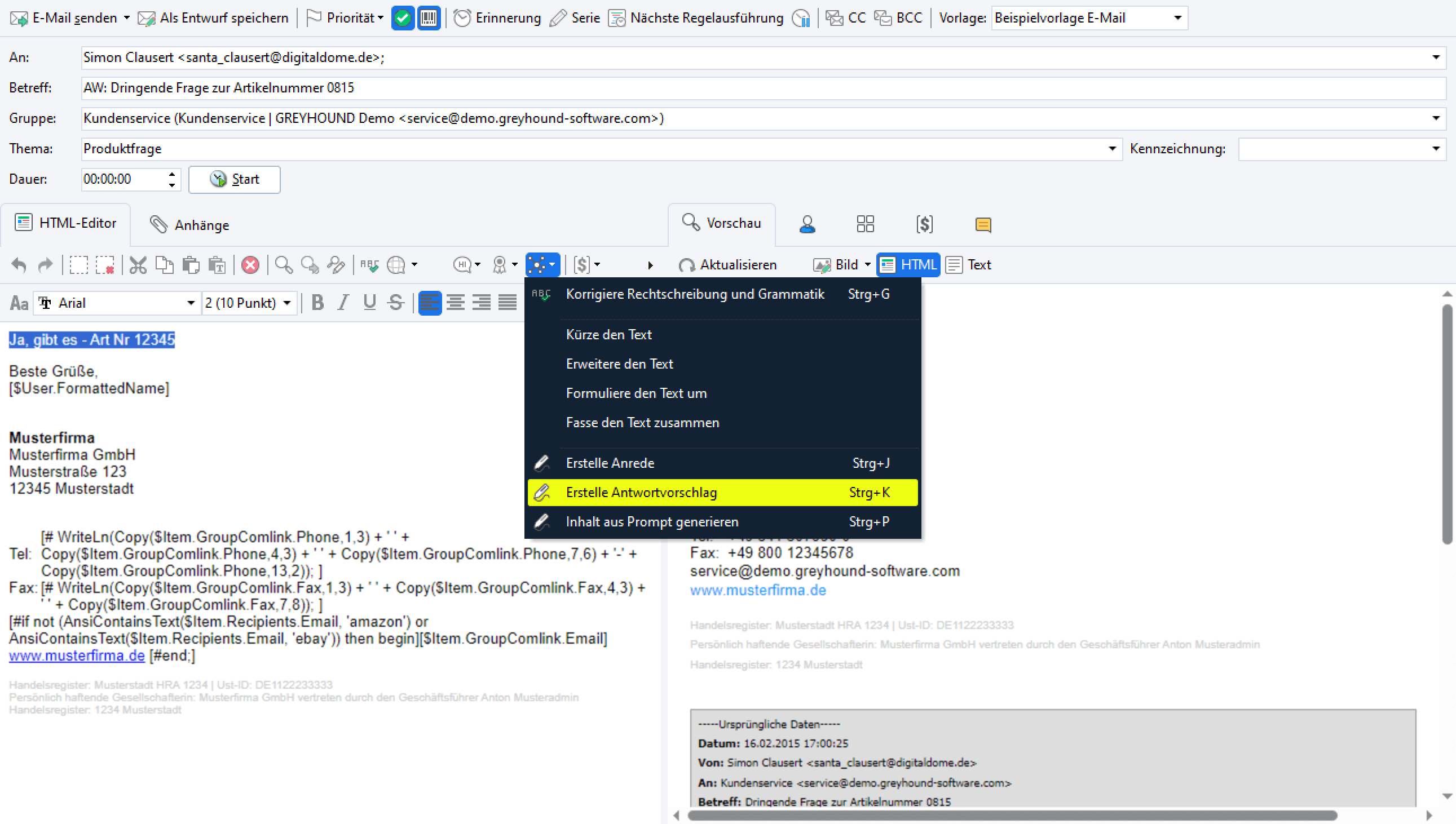
Step 3 – die Antwort:
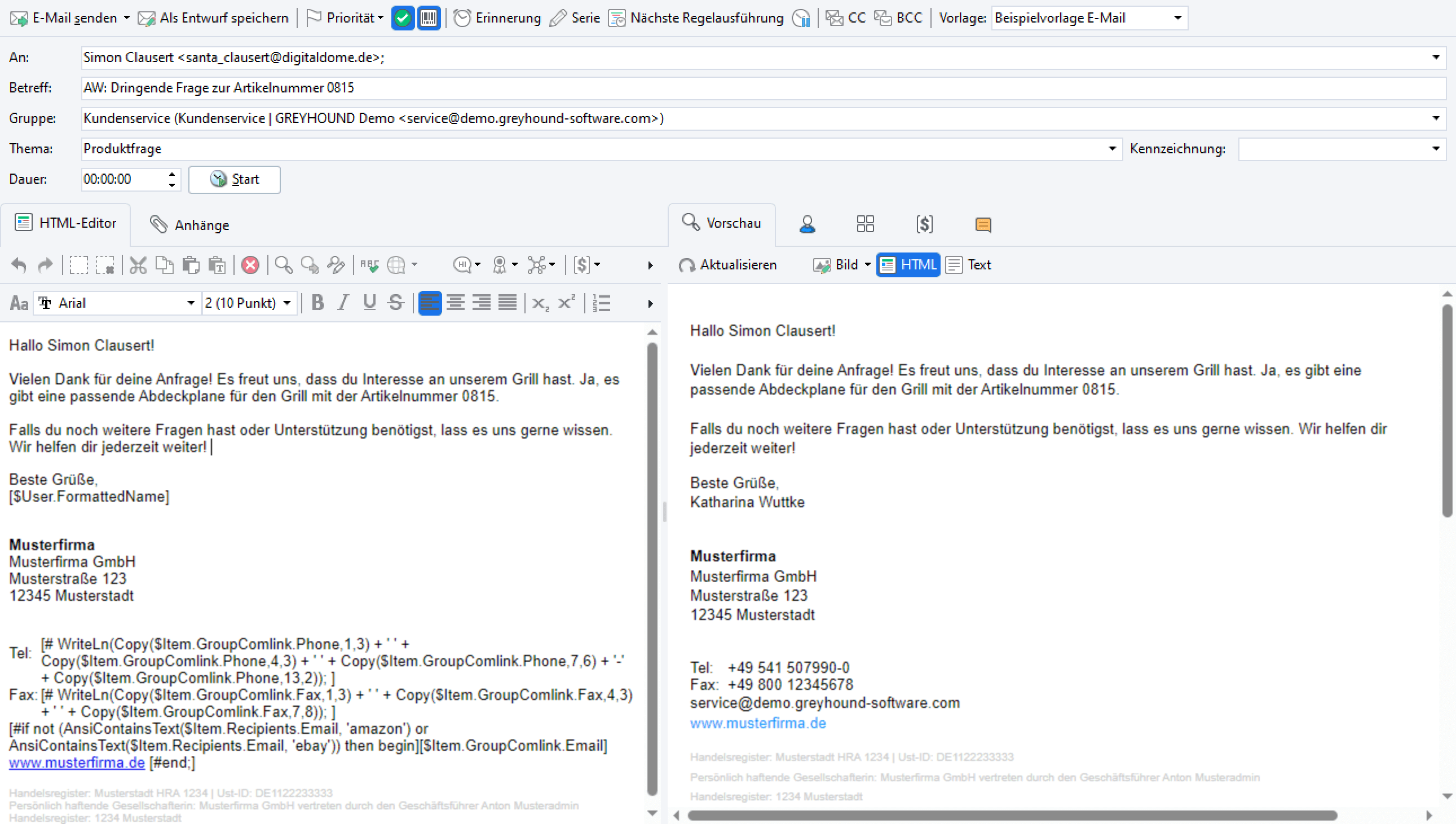
Der KI-Antwortvorschlag funktioniert nur, wenn auf eine Anfrage geantwortet wird, also bereits ein Anliegen da ist, auf das reagiert wird.
Der KI-Antwortvorschlag greift, sofern vorhanden, auf Addon-Daten aus angebundenen Drittsystemen zurück und gibt diese Werte auch aus. So sind Texte in sprachlich guter Qualität, angereichert mit individuellen Informationen wie Kundennummer, Bestellnummer, Trackinglink etc. innerhalb von Sekunden von der KI formuliert.
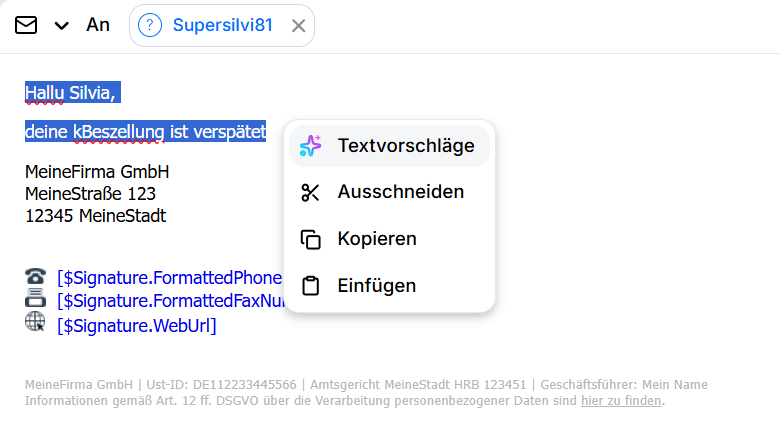
Texte optimieren & korrigieren
Um Texte zu optimieren und zu korrigieren, einfach den betreffenden Text markieren, Rechtsklick und “Textvorschläge” auswählen:
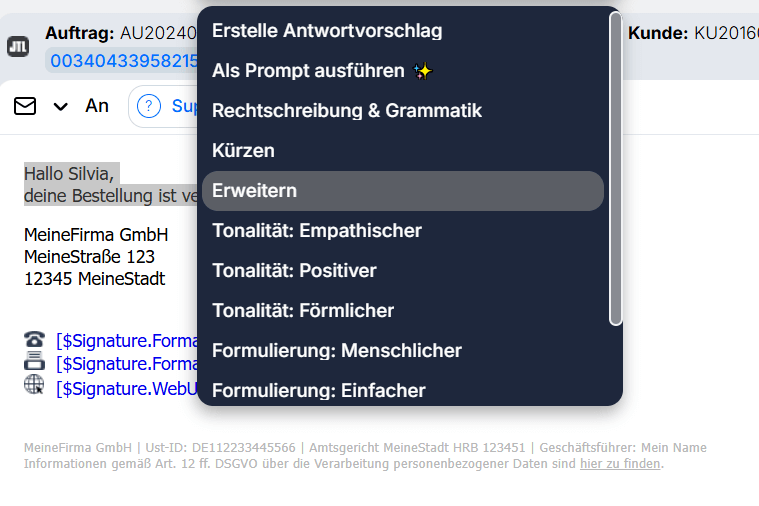
Dort steht eine Reihe an KI-Funktionen zur Verfügung:
Wählt man eine aus, beginnt die KI zu arbeiten und wenige Sekunden später erscheint der überarbeitete Text:
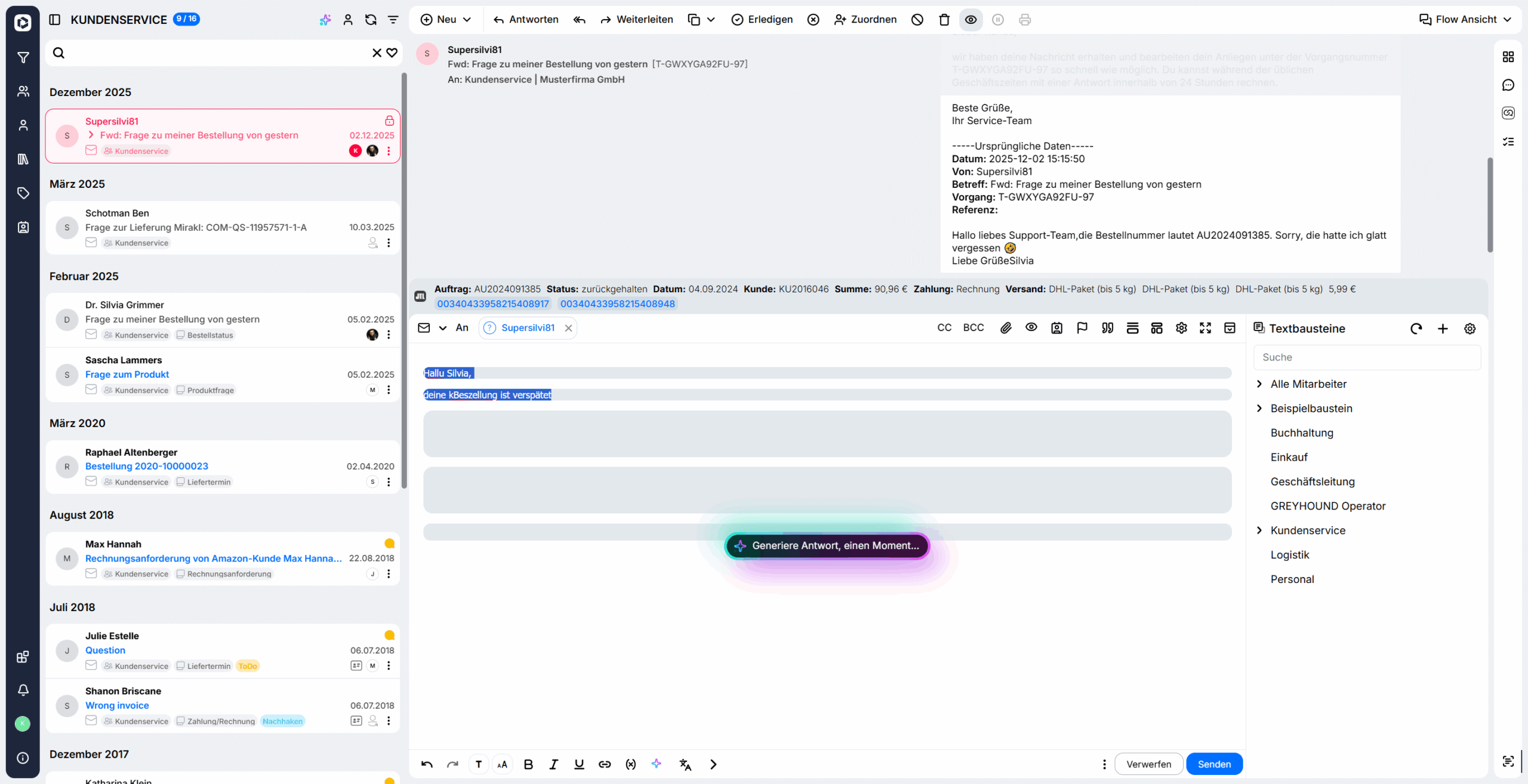
Eine große Hilfe ist die KI aktuell vor allem in Sachen “Text”: Sie kann Texte in der richtigen Tonalität erstellen, Texte kürzen oder umschreiben. Auch eine Prüfung auf Rechtschreib- und Grammatikfehler ist möglich – und das in allen Sprachen! Konkret geht in GREYHOUND derzeit Folgendes:
- Korrigiere Rechtschreibung und Grammatik
- Kürze den Text
- Erweitere den Text
- Formuliere den Text um
- Fasse den Text zusammen
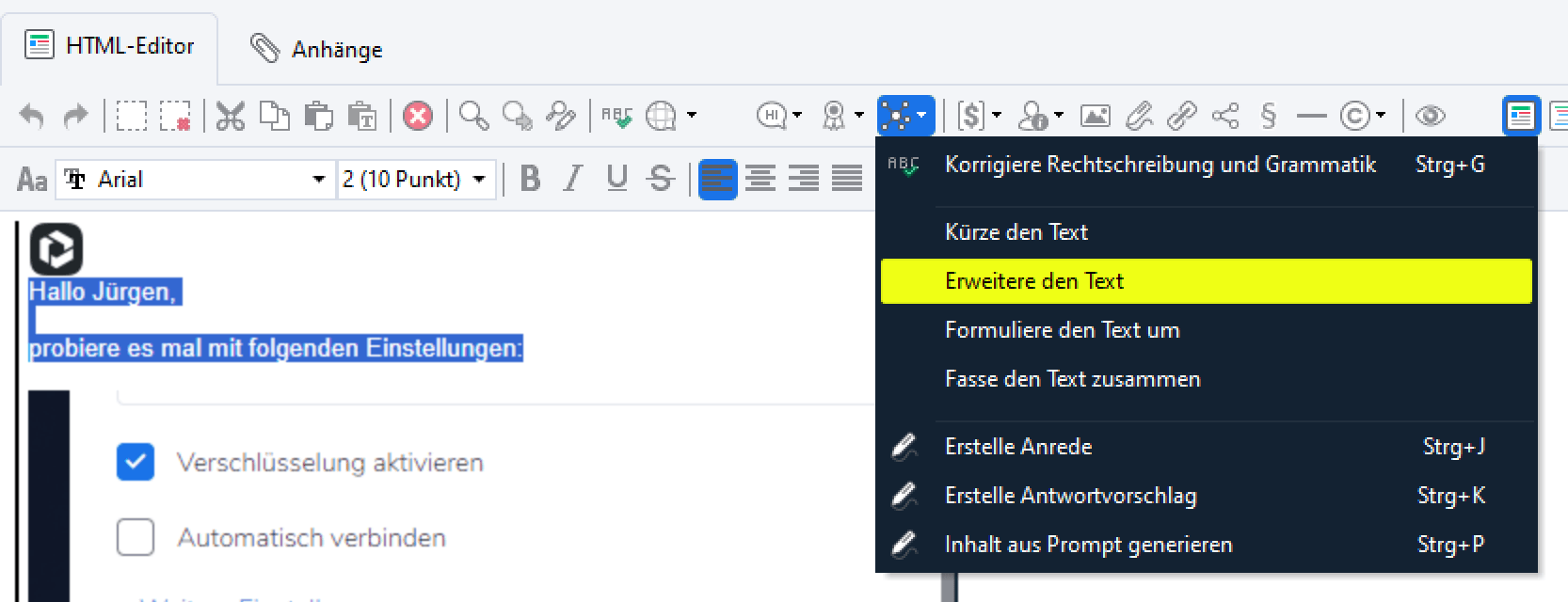
Wichtig: Der Text bzw. Abschnitt, auf den man die KI-Funktionen anwenden möchte, muss zuvor markiert werden. Anschließend mit Rechtsklick > KI basierten Inhalt generieren die gewünschte Funktion wählen.
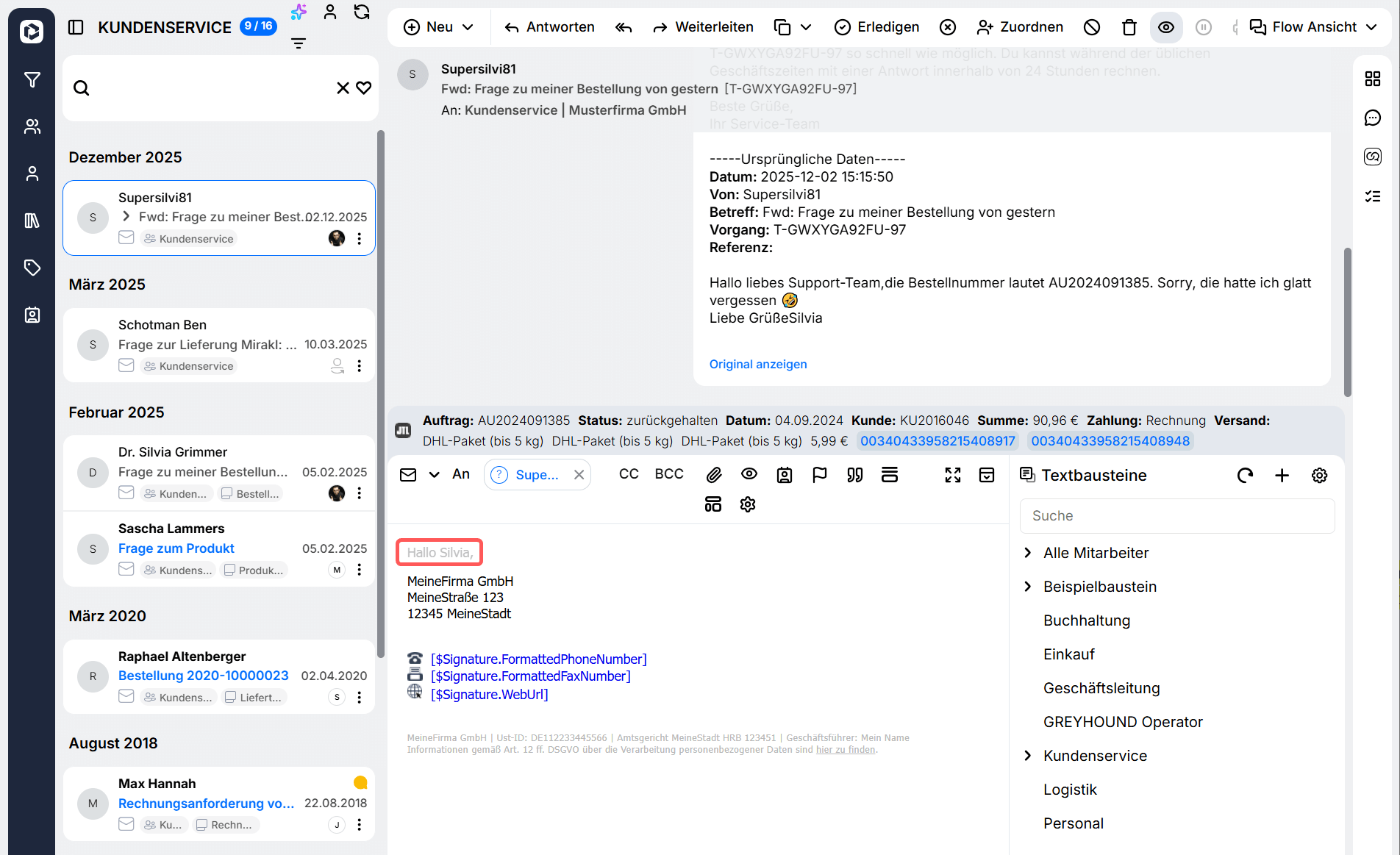
Anrede automatisch erkennen & einfügen
In GREYHOUND kann eine Anrede auch KI-gestützt generiert werden. Voraussetzung ist, dass bereits eine Anfrage vorliegt, auf die geantwortet wird.
Im Webclient passiert das ganz von allein – inklusive zur Anfrage passender Tonalität (“Liebe Gisela”; “Guten Tag Herr Müller” etc.). Der Anrede-Vorschlag wird in grau dargestellt und kann durch Drücken den Tab-Taste eingefügt werden:
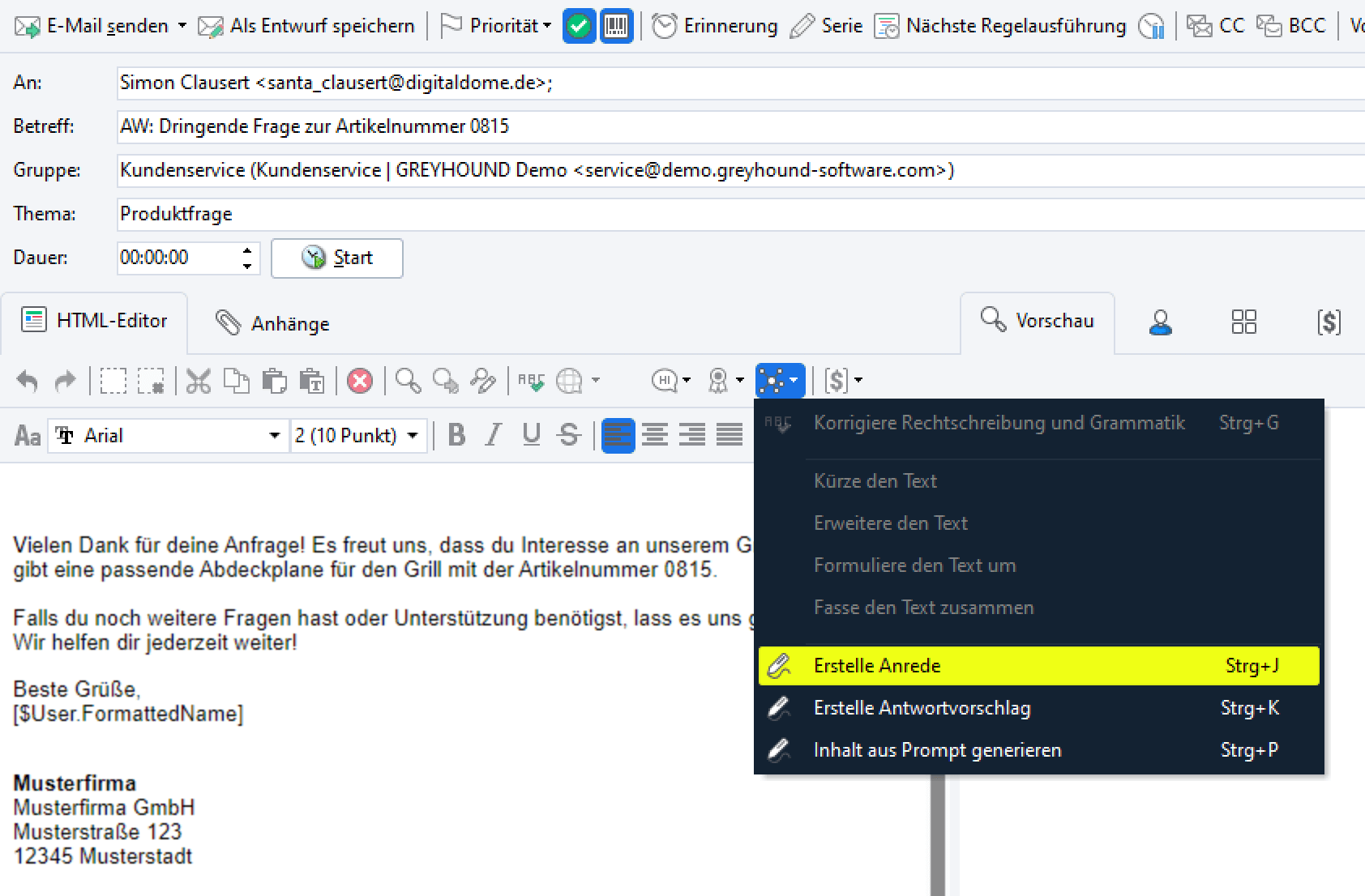
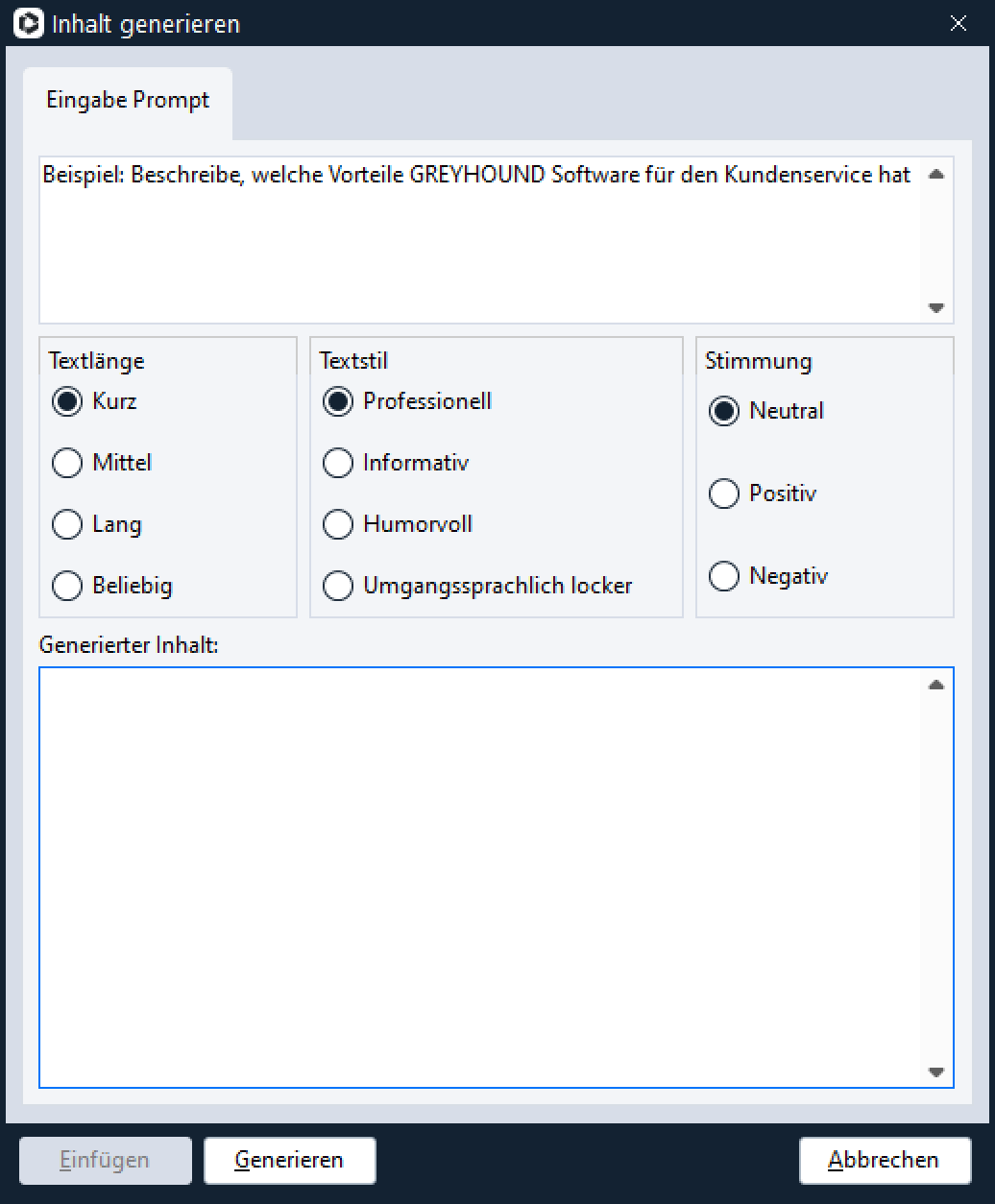
Inhalt aus Prompt generieren
Mir Rechtsklick > Textvorschläge > Inhalt aus Prompt generieren lassen sich Textvorschläge genau steuern: Es ist möglich, beliebige Prompts einzugeben und Details wie Textlänge, Textstil und Stimmung zu bestimmen kann.
Warum das wichtig ist? Weil die KI tendenziell immer die Antwort gibt, die das Gegenüber vermeintlich hören will. Will man dem Kunden eine “negative” Nachricht überbringen, z. B. “Nein, ein Umtausch ist nicht möglich”, dann ist dies durch die Auswahl einer negativen Stimmung möglich. Diese Option heißt nicht, dass die Antwort miesgelaunt formuliert ist, sondern dass entspricht eher einer “ablehnenden”, “verneinenden” Haltung.
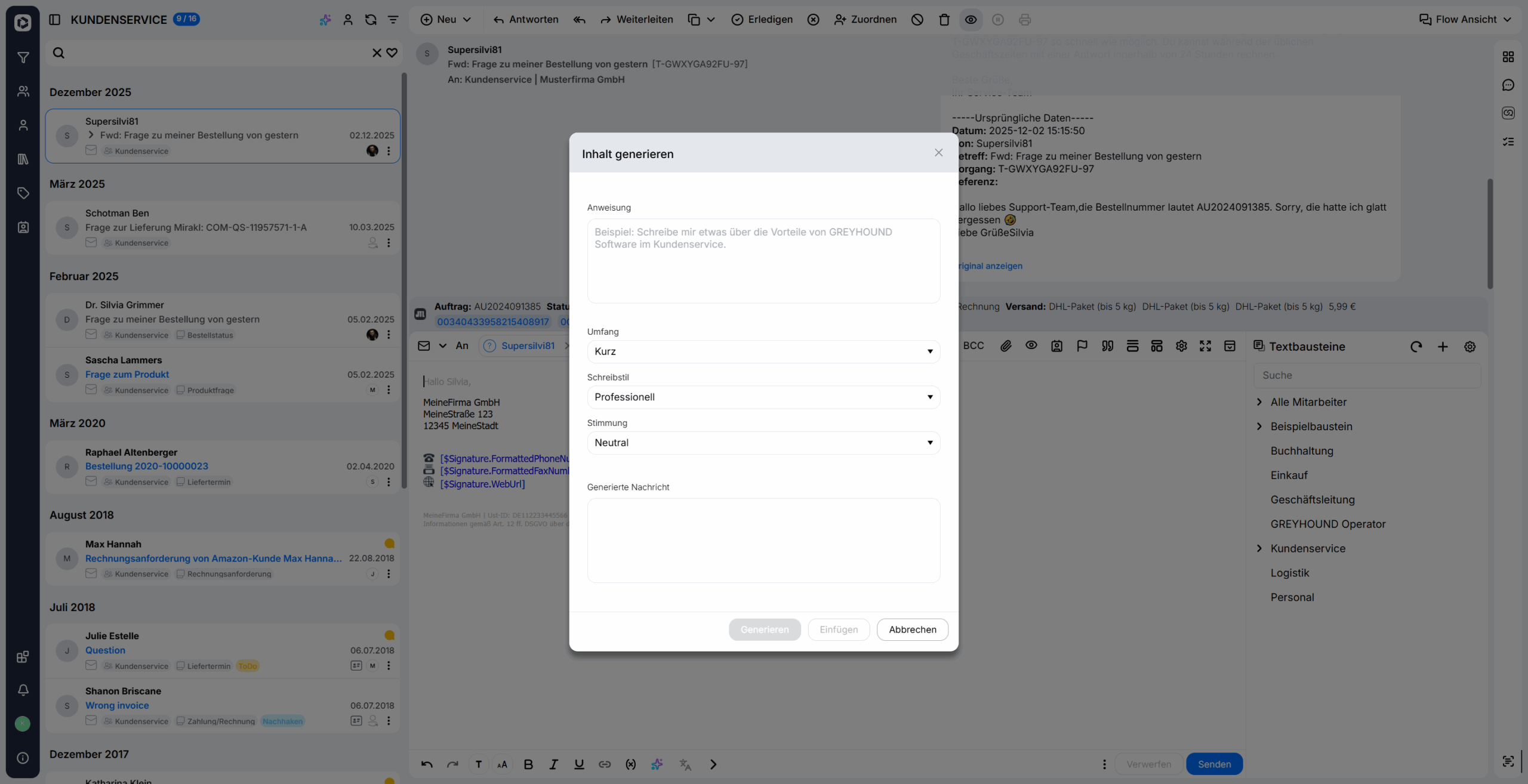
Klickt man auf den Button “KI basierten Inhalt erstellen“, taucht ganz unten der Punkt “Inhalt aus Prompt generieren“, in dem eine ganze Menge steckt:
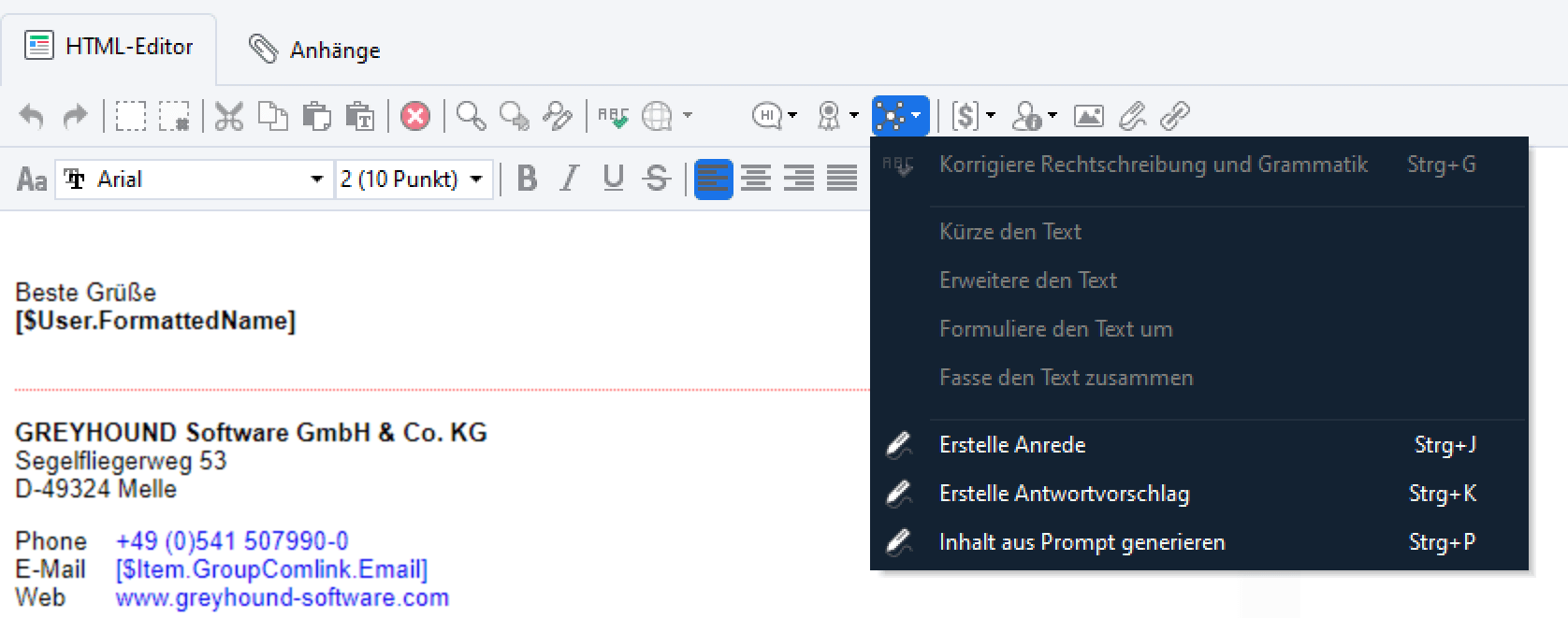
Klickt man den Punkt an öffnet sich ein Fenster, in das man ein beliebiges Prompt eingeben sowie Textlänge, Textstil und Stimmung bestimmen kann. Tipp: Die KI gibt tendenziell immer die Antwort, die das Gegenüber vermeintlich hören will. Will man dem Kunden eine “negative” Nachricht überbringen, z. B. “Nein, ein Umtausch ist nicht möglich”, dann ist dies durch die Auswahl einer negativen Stimmung möglich. Diese Option heißt nicht, dass die Antwort miesgelaunt formuliert ist, sondern dass entspricht eher einer “ablehnenden”, “verneinenden” Haltung.
Durch Klick auf den Button “Generieren” wird ein Textvorschlag durch die künstliche Intelligenz erstellt, der durch “Einfügen” direkt in das Element übernommen werden kann:
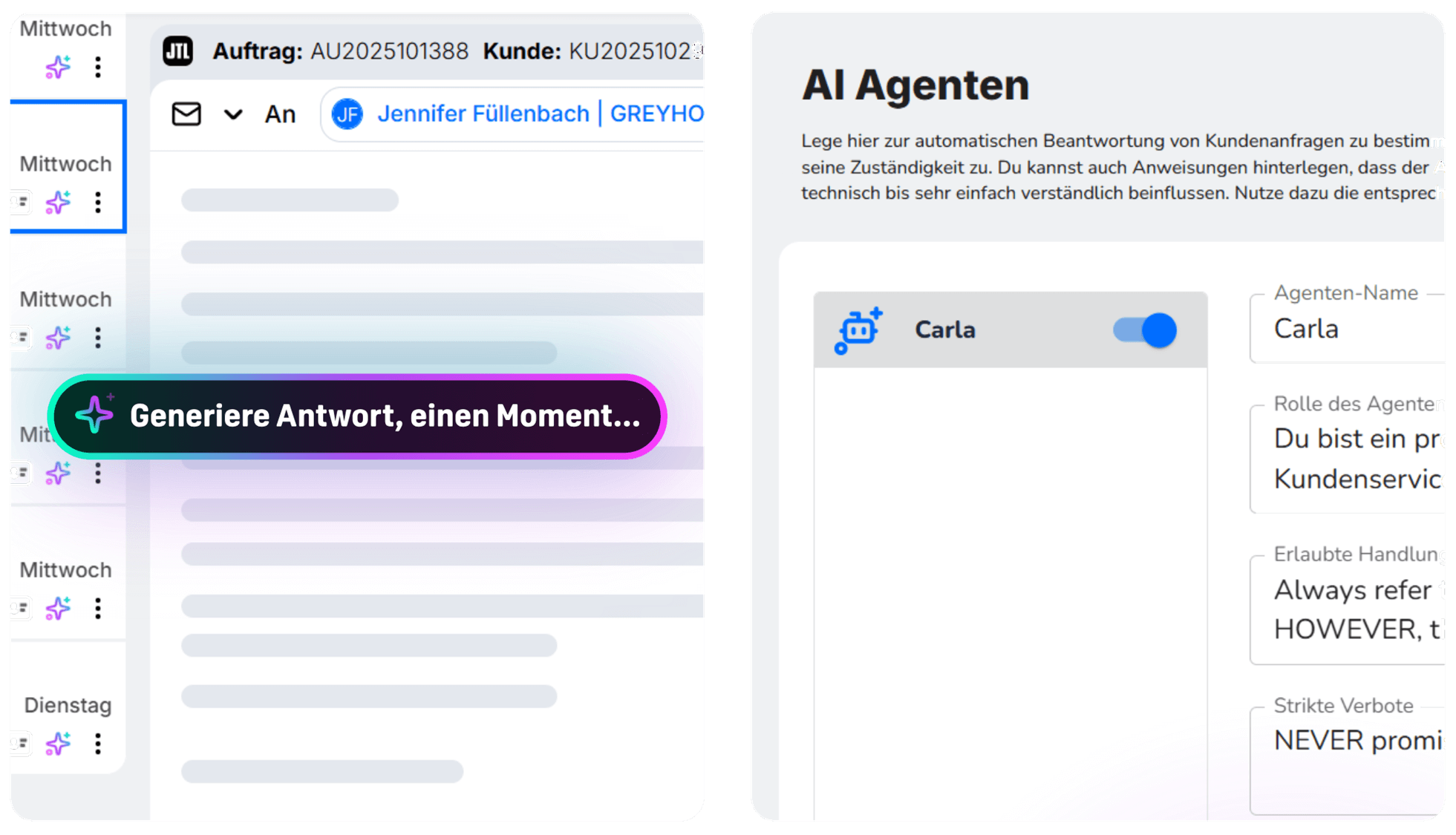
KI nutzen: AI Agent
Der AI Agent kann automatisch auf Standardanfragen antworten. Die Einrichtung & Konfiguration erfolgt über die Einrichtungshilfe (via Webclient oder Windows Client).
KI Agent einrichten
Der AI Agent ist über die Einrichtungshilfe im Webclient zu konfigurieren:
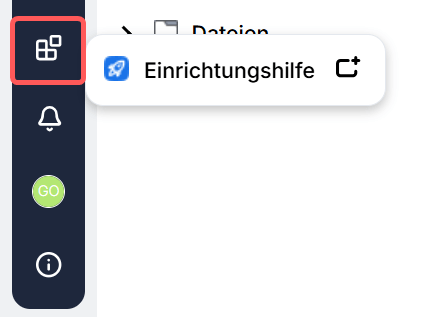
In der Einrichtungshilf bitte zum Punkt “KI-Agenten” navigieren und auf den Hinzufügen-Button klicken:

Hier ist folgendes zu definieren:
- Zunächst ist dem KI-Agenten ein beliebiger Name zu geben.
- Anschließend muss eine Beschreibung der Rolle des Agenten erfolgen.
- Optional sind erlaubte Handlungen zu definieren (z. B. auf die Webseite zur Lieferkonditionen verlinken) oder strikte Verbote (z. B. keine Preisversprechen geben).
- Wenn “Signatur hinzufügen” aktiv ist, wird der KI-Agent seine eigene Verabschiedung hinzufügen und nicht die Standard-Signatur wählen.
- Optional ist eine Antwortsprache definieren – kann auch leer bleiben, dann antwortet der Agent in der Sprache der Anfrage.
- Weiterhin ist die Tonalität zu bestimmen: Soll der Agent eher formell oder persönlich antworten? Eher prägnant oder ausführlich?
- Die wichtigste Stellschraube sind die Themenschwerpunkte. Über die Themen wird gesteuert, auf welche Anfragen der Agent automatisch antworten soll.
- Wir empfehlen aktuell folgende Themen: Lieferstatus, Bestellstatus und/oder Erstattung.
- Ist das ausgewählte Thema grau hinterlegt, bedeutet das, dass der Agent lediglich einen Antwortvorschlag erstellt (empfohlen). Klickt man das Thema einmal an, wird es blau hinterlegt, was bedeutet, dass vollautomatisch geantwortet wird.
- Im letzten Schritt werden die Zugriffsberechtigung auf Abteilungen anhand der Benutzergruppen festgelegt.
- Zum Abschluss noch auf “Abschließen” klicken und “Anwenden” wählen.


Es können beliebig viele KI Agenten angelegt werden für unterschiedliche Themen, Sprachen etc.
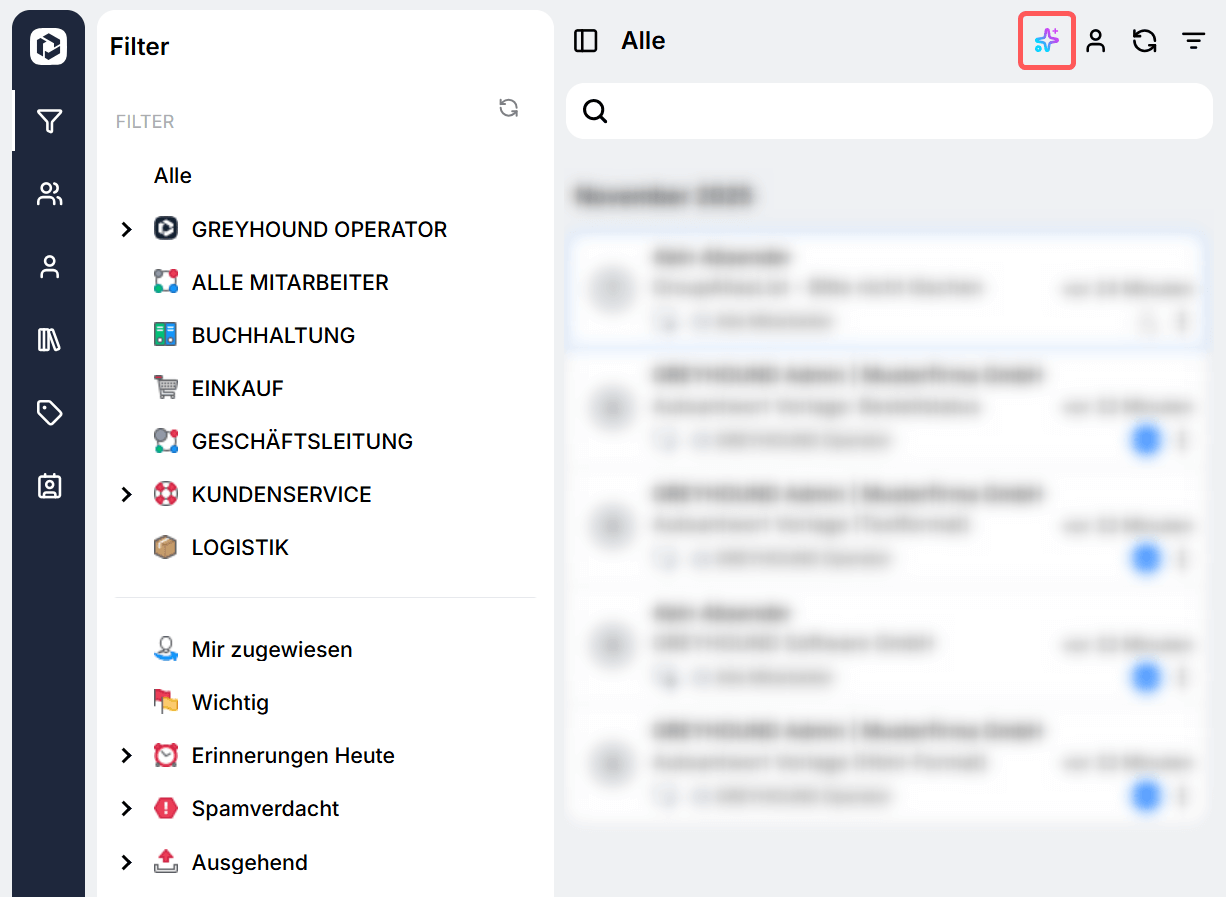
Antworten des KI Agenten prüfen
Über folgenden Button lassen sich die vom KI Agenten formulierten KI-Entwürfe anzeigen und prüfen sowie manuell versenden:
FAQ
Ja. Unter Administration > OpenAI Embeddings zurücksetzen kann das gesammelte Wissen bei Bedarf wieder “entlernt” werden:
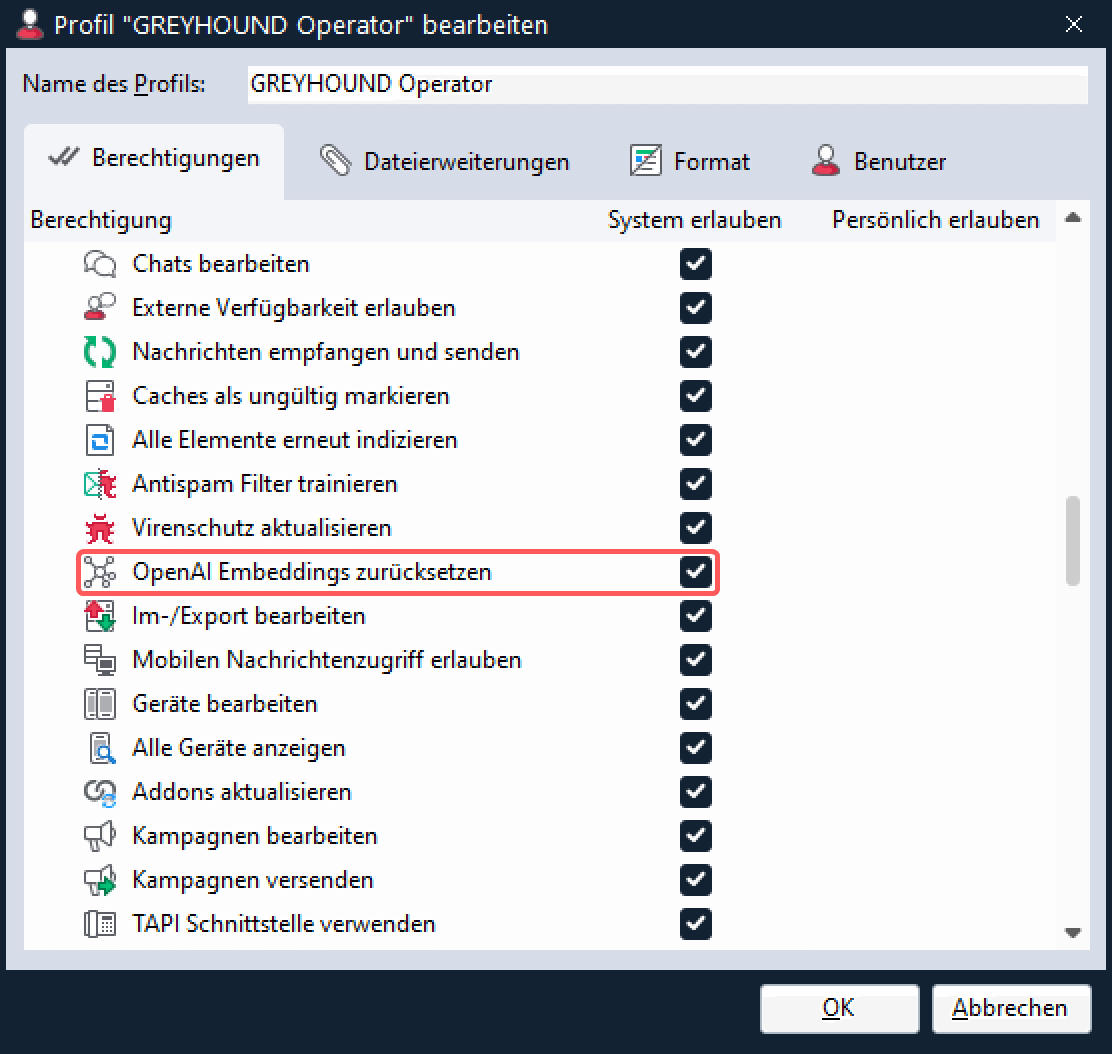
Dieses Recht sollte nur für den GREYHOUND Operator und/oder diejenigen anderen Profile freigeschaltet sein, deren Mitglieder die Künstliche Intelligenz in GREYHOUND konfigurieren können sollen:
Achtung: Jede Berechnung dauert einige Sekunden und kann den Queueserver erheblich ausbremsen – diese Funktion ist deshalb nur für größere Kunden mit mindestens 2 Queueserver-Threads zu empfehlen!
Hinweis für Eigenbetriebler: Die dateibasierten Vektordatenbank befindet sich unterhalb der Server Verzeichnisses im Ordner EmbeddingIndex:

Rechtliches & Datenschutz
DSGVO-Konformität
Wer die AI Agents und/oder AI Human Assist nutzt, für den wird die JTL-Software-GmbH auf vertraglicher Grundlage als Auftragsverarbeiter tätig. Dieser Einsatz erfolgt datenschutzkonform. Weitere Informationen sind in unserer Datenschutzerklärung zu finden.
Transparenzpflicht gemäß EU AI Act
Bei vollautomatisierten KI-Antworten kann für Anwender der KI in GREYHOUND gegenüber ihren Kunden/Kommunikationspartnern eine Transparenzpflicht nach dem EU AI Act bestehen. Bitte berücksichtigt interne Compliance- oder Branchenanforderungen, z. B. in Form eines Hinweises in der Signatur bei KI-generierten Nachrichten wie “Dieses Anliegen wurde mit KI-Unterstützung beantwortet“.
Hinweis: Wir können an dieser Stelle keine (datenschutz-)rechtliche Beratung für unsere Kunden leisten.