
Kontaktbasierte Dokumentenanalyse
Im Standard-Setup von GREYHOUND gibt es eine Regel namens „Kontaktbasierte Dokumentenanalyse“ (diese kann bei Bedarf hier kostenlos heruntergeladen werden). Diese Regel macht Folgendes: Wenn einem Dokument ein Kontakt zugewiesen ist, dann versucht die Regel auf Basis dessen die Metadaten wie Belegtyp, Belegdatum etc. automatisch mit hoher Trefferquote zu erkennen. Wie das geht? In dem beim jeweiligen Kontakt entsprechende Informationen hinterlegt werden, wie beispielsweise, dass Rechnungen vom Kontakt „Musterlieferant 3001“ stets eine Rechnungsnummer haben, die mit „RE“ beginnt, gefolgt von 8 Ziffern – außerdem steckt im Dateinamen der Rechnungsdokumente von „Musterlieferant 3001“ immer der Name „Invoice“.
Wenn man GREYHOUND solche Informationen einmal „beibringt“, dann ist es mithilfe der Regel zur kontaktbasierten Dokumentenanalyse möglich, sämtliche Dokumententypen zweifelsfrei als solche erkennen und die entsprechenden Belegdaten-Felder zuverlässig füllen zu können.
Wichtig
Prinzipbedingt kann die kontaktbasierte Dokumentenanalyse natürlich nur dann funktionieren, wenn zuvor zweifelsfrei der richtige Kontakt erkannt wurde. Weitere Infos für eine perfekte, automatische Kontaktzuordnung sind hier zu finden.
Wie funktioniert die kontaktbasierte Dokumentenanalyse?
Für jeden Kontakt lassen sich individuelle Schemata hinterlegen, wie die jeweiligen Belegdaten bei diesem Absender aufgebaut sind. So lässt sich zum Beispiel für den Kontakt „Autohaus Superschnell“ im Feld „Erkennungsmaske Belegdatum“ einmal zentral hinterlegen, dass das Format bei Dokumenten dieses Absenders immer im Format „TT.MM.JJJJ“ angegeben sind. Das erleichtert die automatische Dokumentenanalyse und verbessert ihre Trefferquote enorm.
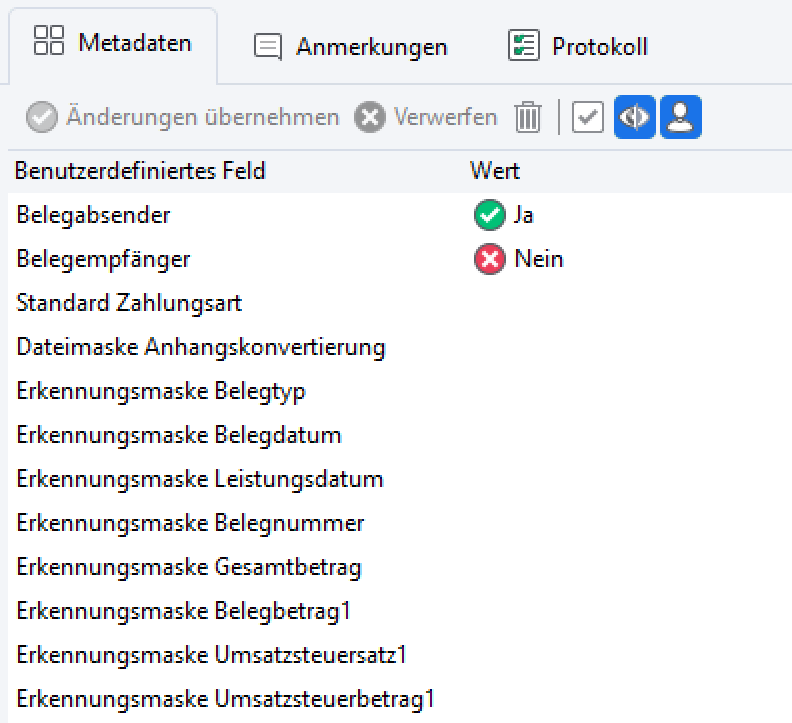
Derzeit unterstützt diese Regel folgende Metadaten-Felder:
- Belegtyp
- Belegdatum
- Leistungsdatum
- Belegnummer
- Gesamtbetrag
- Belegbetrag1
- Umsatzsteuersatz1
- Umsatzsteuerbetrag1
Die zusätzlichen Metadaten-Felder werden sichtbar, sobald ein Kontakt als Belegabsender klassifiziert ist. Nutzer älterer GREYHOUND-Version müssen die nötigen benutzerdefinierten Felder ggfs. manuell anlegen.
Wie werden die Erkennungsmasken gefüllt?
In die Erkennungsmasken werden reguläre Ausdrücke eingetragen. Diese sind in den jeweiligen benutzerdefinierten Feldern beim Kontakt einzutragen und werden dann automatisch für die Dokumentenanalyse herangezogen, bei denen der Kontakt als Absender ausgewählt wurde.
Im Folgenden werden die einzelnen Erkennungsmasken jeweils anhand von Praxis-Beispielen näher erläutert:
Beispiel: Belegtyp
Die Maske für den “Belegtyp” folgt einem besonderen Format:
- Erkennungsformat: Belegtyp=Erkennungsmaske:::Belegtyp=Erkennungsmaske
- Ergebnistyp: Match (Heißt: Wenn der Regex genau passt, wird der Belegtyp zugewiesen)
Beispiel 1: Gutschrift=Rechnungskorrektur
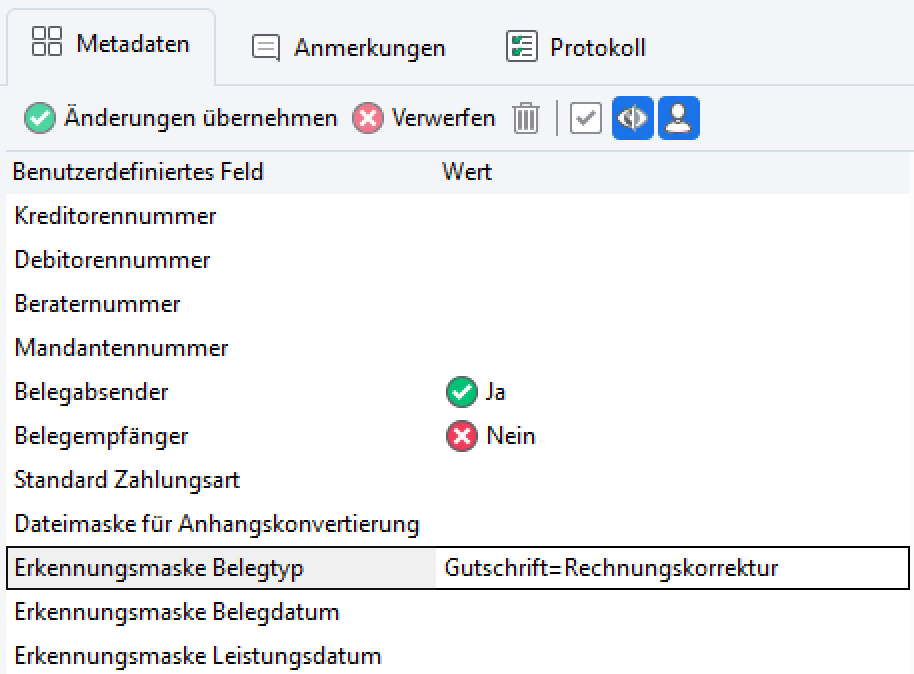
Erklärung: Dem Belegtyp “Gutschrift” (so wie er namentlich im benutzerdefinierten Feld aufgelistet ist) wird mit dem “=” das Wort “Rechnungskorrektur” zugewiesen, weil dieses auf dem Gutschrifts-Beleg irgendwo vorkommt.
Beispiel 2: Gutschrift=Rechnungskorrektur|GS-20[0-9]{4}
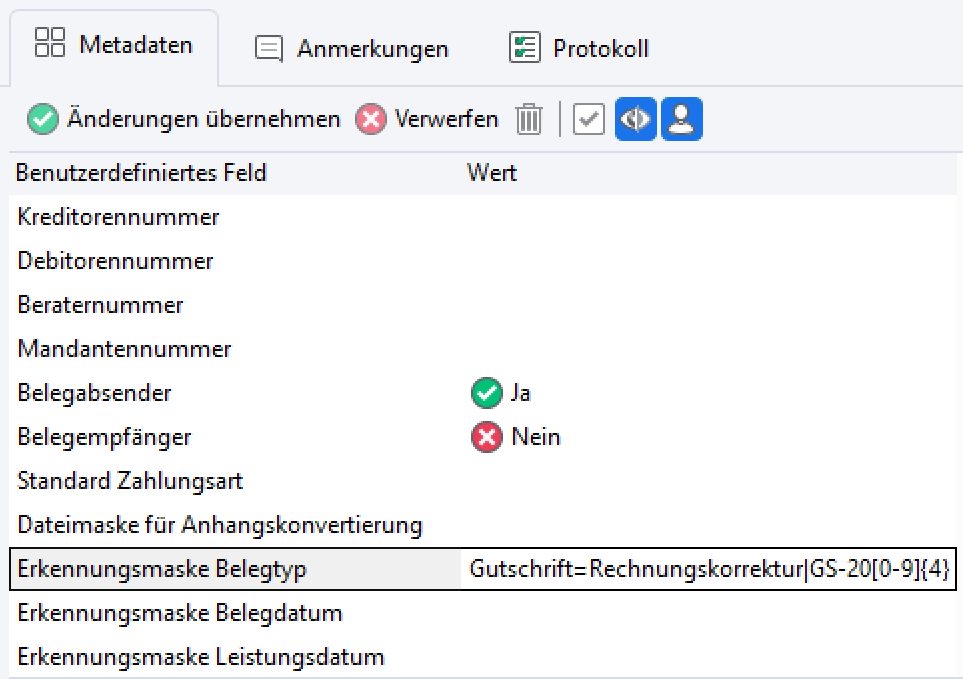
Erklärung: Wie Beispiel 1, nur dass zusätzlich auch die Zeichenkette “GS-20”, gefolgt von einer 4-stelligen Zahl, ein eindeutiges Erkennungsmerkmal für eine Gutschrift ist. Die beiden Zeichenketten wurden hier mit dem Pipe-Symbol “|” getrennt.
Beispiel 3: Rechnung=R E C H N U N G:::Gutschrift=G U T S C H R I F T
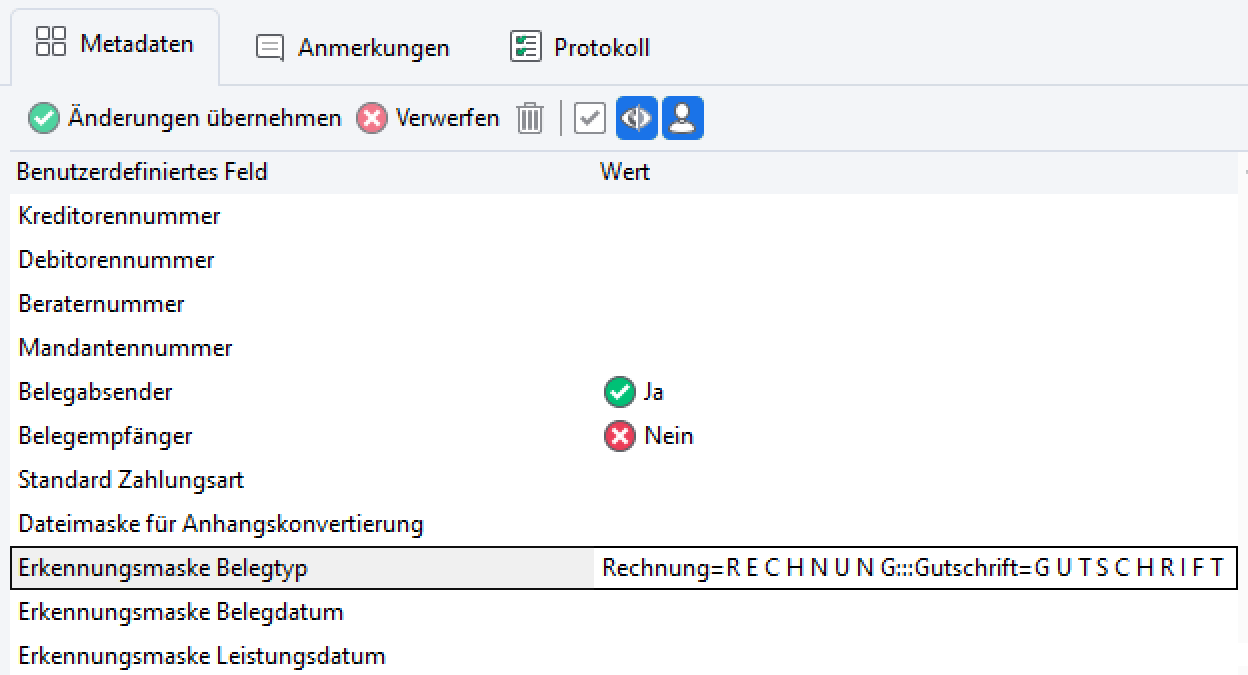
Erklärung: Die Zeichenkette “R E C H N U N G” klassifiziert den Beleg eindeutig als Rechnung. Getrennt von dem dreifachen Doppelpunkt “:::” wurde für den Belegtyp Gutschrift eine andere Erkennungsmaske hinterlegt.
Hinweis
Es können beliebig viele Erkennungsmasken für mehrere Belegtypen hinterlegt werden. Diese müssen jeweils durch “:::” getrennt werden.
Beispiel: Belegdatum, Leistungsdatum, Belegnummer, Gesamtbetrag, Belegbetrag1, Umsatzsteuersatz1, Umsatzsteuerbetrag1
- Erkennungformat: Regulärer Ausdruck
- Ergebnistyp: Extract (Heißt: Der gesuchte Wert muss in $1 enthalten sein. $0 wird von der Regel als Fallback geprüft, aber es ist von dem jeweiligen Ergebnis abhängig, ob daraus der gewünschte Wert ermittelt werden kann.)
Beispiel 1: Belegbetrag1
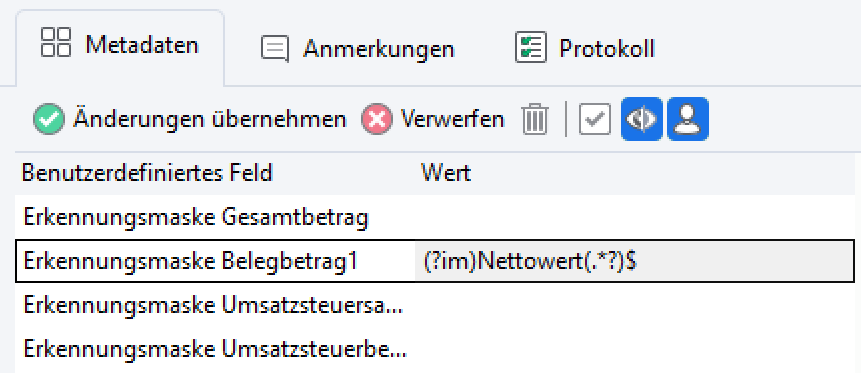
Im Feld “Erkennungsmaske Belegbetrag1” steht folgende Maske: (?im)Nettowert(.*?)$
Erklärung: Der gewünschte Netto-Belegbetrag steht stets hinter dem ersten Vorkommen des Wortes “Nettowert” und bildet auch das Zeilenende. Die Groß- und Kleinschreibung wird ignoriert.
Beispiel 2: Gesamtbetrag
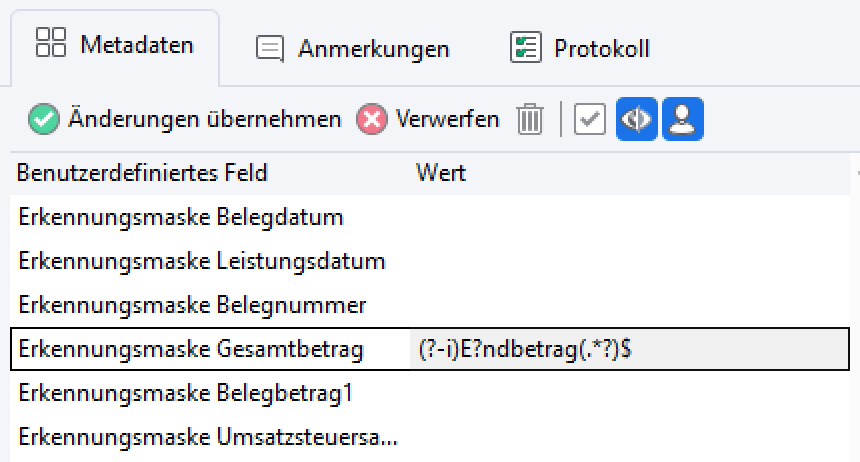
Im Feld “Erkennungsmaske Gesamtbetrag” steht folgende Maske: (?-i)E?ndbetrag(.*?)$
Erklärung: Der gewünschte Gesamtbetrag steht stets hinter dem ersten Vorkommen des Wortes “Endbetrag” am Ende einer Zeile. Der erste Buchstabe “E” ist optional, weil er aufgrund des Rechnungslayouts beim Scannen manchmal nicht korrekt erkannt wird. Die Groß- und Kleinschreibung wird respektiert.
Beispiel 3: Leistungsdatum
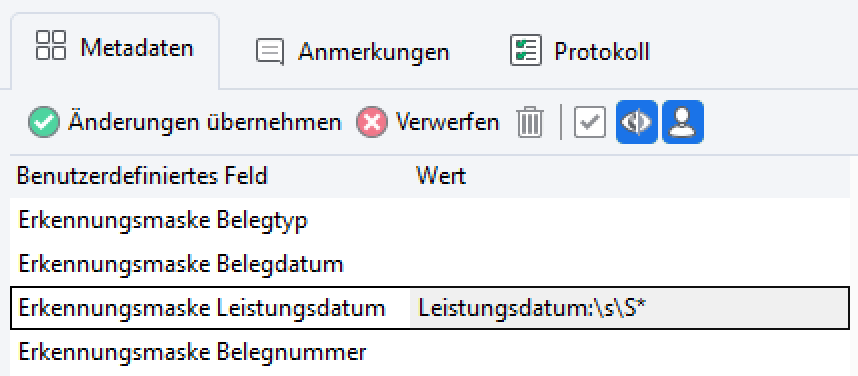
Im Feld “Erkennungsmaske Leistungsdatum” steht folgende Maske: Leistungsdatum:\s\S*
Erklärung: Hinter dem Wort “Leistungsdatum:”, gefolgt von einem Whitespace-Zeichen, steht das Datum in der Schreibweise “TT.MM.YYYY”. Der Ausdruck erkennt mangels Klammern “()” die gesamte Zeichenkette in $0 (Das Ergebnis in $0 enthält dann beispielsweise “Leistungsdatum: 31.01.2015”. $1 bleibt leer.) Da im Ergebnis jedoch nur ein Datum enthalten ist, findet die Regel das Datum dennoch. Die Verwendung des Ausdrucks “Leistungsdatum:\s(\S*)” (Klammern beachten) wäre eindeutiger gewesen, weil dann in $1 nur das Datum gestanden hätte. Da das Datum sich in diesem Fall aber eindeutig vom restlichen Text unterscheidet, sind die Klammern in diesem Fall kein Muss.
Wichtige Hinweise
- Für alle Felder: Die Regel versucht automatisch den in $1 gefundenen Wert zu serialisieren und in das richtige Format umzuwandeln. Es ist beispielsweise nicht nötig, das “%”-Zeichen ein- oder auszuschließen, um den Steuersatz von 19% zu erkennen.
- Für Datumsfelder: Es werden alle möglichen Schreibweisen eines Datums erkannt, sofern dieses plausibel ist. So werden beispielsweise die Schreibweisen “Nov 11 2022”, “2022-12-31” und “29.02.2022” korrekt erkannt, das Datum “2022/03/02” aber möglicherweise als 02. März 2022, obwohl der Absender den 03. Februar 2022 meinte.
Tipps
Das Erstellen von Masken mithilfe von regulären Ausdrücken kann mit geeigneten Werkzeugen deutlich vereinfacht werden. Dazu gibt es auch reine Online-Werkzeuge, wie beispielsweise https://regex101.com.
Dort kann man den Text aus GREYHOUND hineinkopieren, und in Echtzeit sehen, ob ein regulärer Ausdruck passt.
Hinweis
GREYHOUND verwendet den sogenannten PCRE-Dialekt (PHP < 7.3) für reguläre Ausdrücke.
Es hat sich bewährt, Ausdrücke stets nach einem ähnlichen Muster zu erstellen. Das hilft beim späteren Verstehen und anpassen. So kann es beispielsweise hilfreich sein, eine Maske stets mit Modifikatoren wie “i”, “m” und “s” zu beginnen, damit die Wirkungsweise des nachfolgenden Ausdrucks eindeutig ist. Ein mit “(?ims)” beginnender Ausdruck lässt direkt erkennen, dass die Groß- und Kleinschreibung egal ist und der Multiline-Modus verwendet werden soll.
Bei der Erstellung von Masken kann die Erkennungsquote verbessert werden, wenn Zeichenfehler durch schlecht gescannte Dokumente berücksichtigt werden. Häufig werden Großbuchstaben wie “O” oder “I” durch Zahlen (oder umgekehrt) ersetzt.
Exkurs: Anhangskonvertierung
Ergänzend hierzu gibt es eine weitere spannende Regel: “Eingangsverarbeitung: Anhangskonvertierung”. In der Praxis ist es so, dass sehr kleine Schriften, z. B. in Fußzeilen von Dokumenten, oder Zeichen vor einem farbigen Hintergrund (z. B. Gesamtbeträge), von der OCR oft nicht leicht zu erkennen sind. Nutzt man die Regel „Eingangsverarbeitung: Anhangskonvertierung“, dann schreibt diese in den Textinhalt des erzeugten Dokumentes den aus den Metadaten des konvertierten Dokuments ermittelten Text. Neben dem von der Texterkennung (OCR) erkannten Text steht der Text aus dem PDF somit zusätzlich als reine Text-Version zur Verfügung. Um eine optimale Erkennungsquote zu erreichen, lohnt es sich also, beide Versionen des Texts (OCR und Text) anzuschauen. Bei den regulären Ausdrücken kann es entsprechend sinnvoll sein, flexibel beide verschiedenen Varianten einzubeziehen. So könnte man beispielsweise auch bestimmen, dass ein Dateianhang, bei dem „RE“ im Dateinamen steckt, als Dokument konvertiert wird, während ein PDF namens „AGB“ hingegen nicht konvertiert werden soll.