
Auswertungen
In diesem Artikel ist beschrieben, wie man Auswertungen & Diagramme in GREYHOUND erstellen kann.
Auswertungen in GREYHOUND
Mit den GREYHOUND Auswertungen lassen sich aus Live-Daten on-the-fly beliebige Statistiken, in GREYHOUND Diagramme genannt, erstellen. Jedes Diagramm hat seine ganz eigene Konfiguration und ist unabhängig von anderen Diagrammen. Mehrere Diagramme lassen sich in GREYHOUND zu einer gemeinsamen Auswertung zusammenfassen. Ebenfalls in der Auswertung wird die gemeinsame Datenquelle festgelegt, welche für die Generierung aller in dieser Auswertung enthaltenden Diagramme zu Grunde gelegt werden soll.
Bevor man beginnt, ist es zunächst ratsam, sich Gedanken darüber zu machen, was man überhaupt auswerten möchte und wie man diese Daten optisch darstellen möchte. Ein empfohlene Vorgehensweise ist des Weiteren, sich erstmal einige einfachere Standarddiagramme zu konfigurieren und abzuspeichern, die dann später jederzeit in beliebigen Auswertungen wieder eingefügt und verwendet werden können. Am besten beginnt man mit der Erstellung eines Diagramms und NICHT mit der Auswertung selbst.
Datenmenge begrenzen: Was auswerten?
Im ersten Schritt gilt es, sich zu überlegen, welche Daten überhaupt in die Auswertung einfließen sollen: Alle Elemente? Oder nur E-Mails? Nur Mails aus dem Kundenservice?
Je nachdem, welche Daten herangezogen werden, fallen die Ergebnisse der Auswertung natürlich sehr unterschiedlich aus. In GREYHOUND wird diese heranzuziehende Datenmenge über einen Filter bestimmt. Je nach Konfiguration dieses Filters lässt sich also das Ergebnis der Statistik maßgeblich beeinflussen und es ist möglich, bestimmte Teildatenmengen aus dem gesamten GREYHOUND-System zu analysieren.
Unsere Empfehlung ist, einen (oder mehrere) spezielle Auswertungsfilter genau für diesen Zweck anzulegen und diese(n) z. B. im Bereich Teamleiter, GREYHOUND Operator oder anderer Stelle zu positionieren, auf die nicht jeder Zugriff hat.
Bei der Konfiguration ist Folgendes zu beachten: Der Filter zeigt nur die Elemente an, auf die der Benutzer, der die Auswertung erstellt, auch Zugriffsrechte hat. Beispiel: Person A, Teamleiter im Kundenservice, erstellt eine Auswertung. In dieser sollen auch die Mails aus der Geschäftsleitung berücksichtigt werden. Nun kann Person A bei der Filterkonfiguration die Gruppe “Geschäftsleiter” anhaken, auch ohne Zugriffsrechte auf diese Gruppe zu haben (Rechtsklick > Alle Gruppen anzeigen). So kann Person A eine Auswertung erstellen, in der die Mails der Abteilung Geschäftsleitung berücksichtigt werden, auch wenn er selbst keine Zugriffsrechte darauf hat. Allerdings sieht er die zugehörigen Elemente im Filter nicht – sie fließen aber halt dennoch in die Auswertung ein.
Beispiel: “Status pro Bearbeiter”
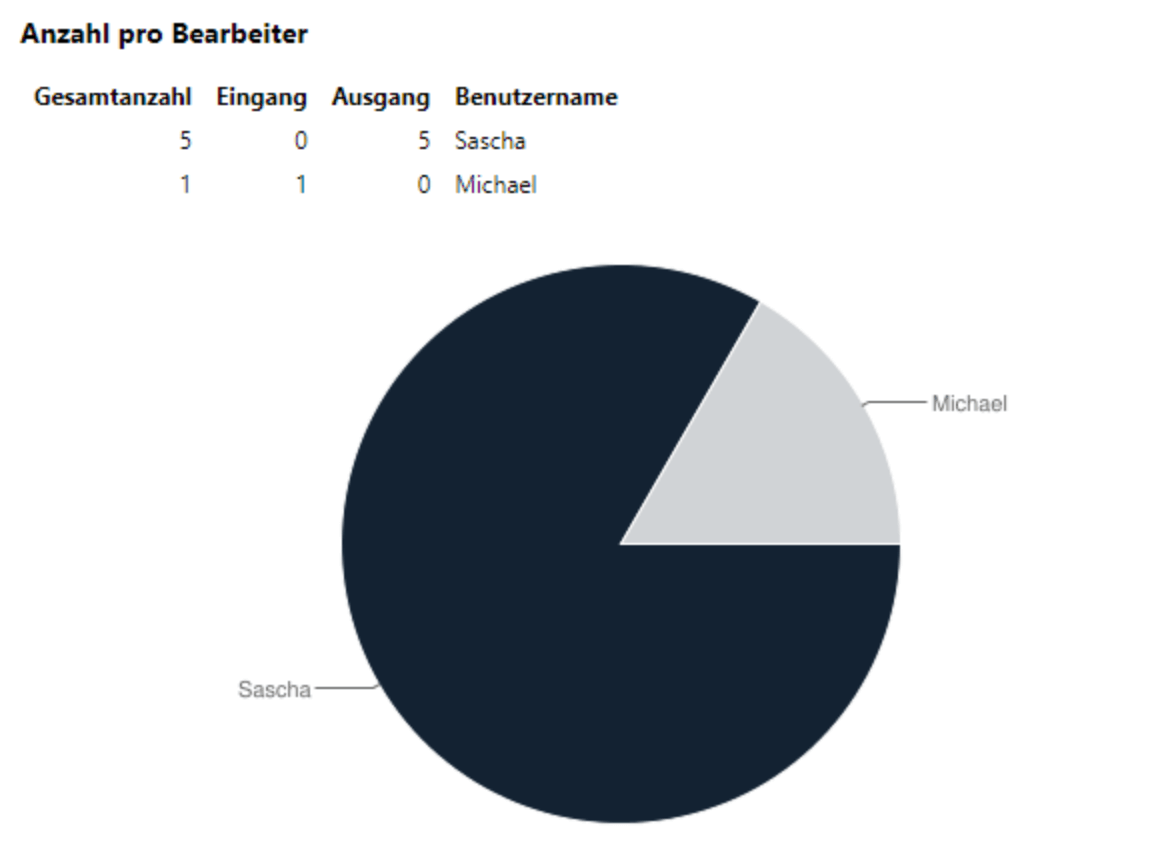
Zum besseren Verständnis beginnen wir mit einem einfachen Beispiel. Wir möchten alle Nachrichten in unserem System nach Status pro Bearbeiter (offen, erledigt, gesendet etc.) gruppiert angezeigt bekommen und dieses Ergebnis grafisch darstellen. Dazu schauen wir uns das im Standard mit ausgelieferte Diagramm mit dem Namen “Status pro Bearbeiter” an:
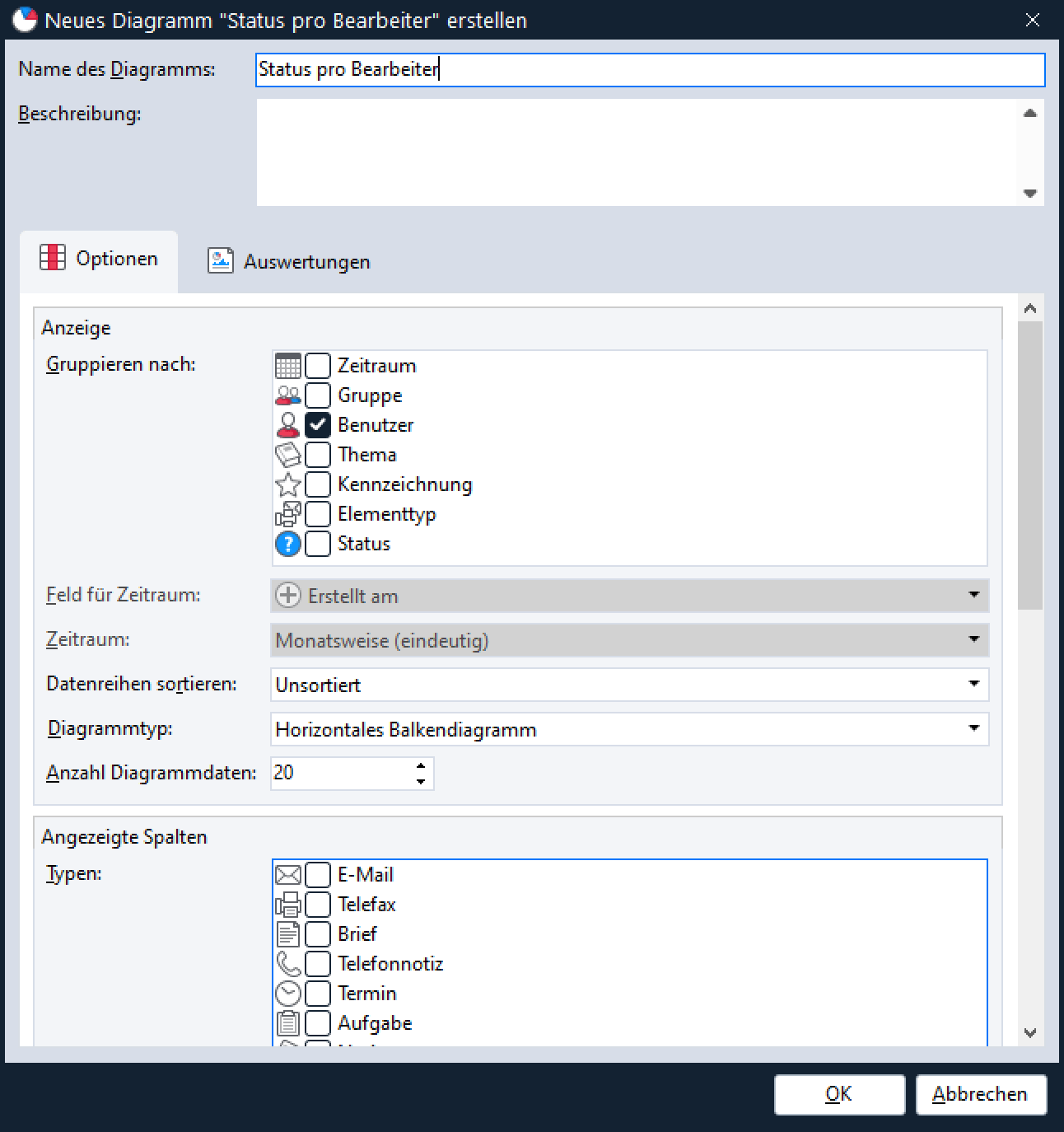
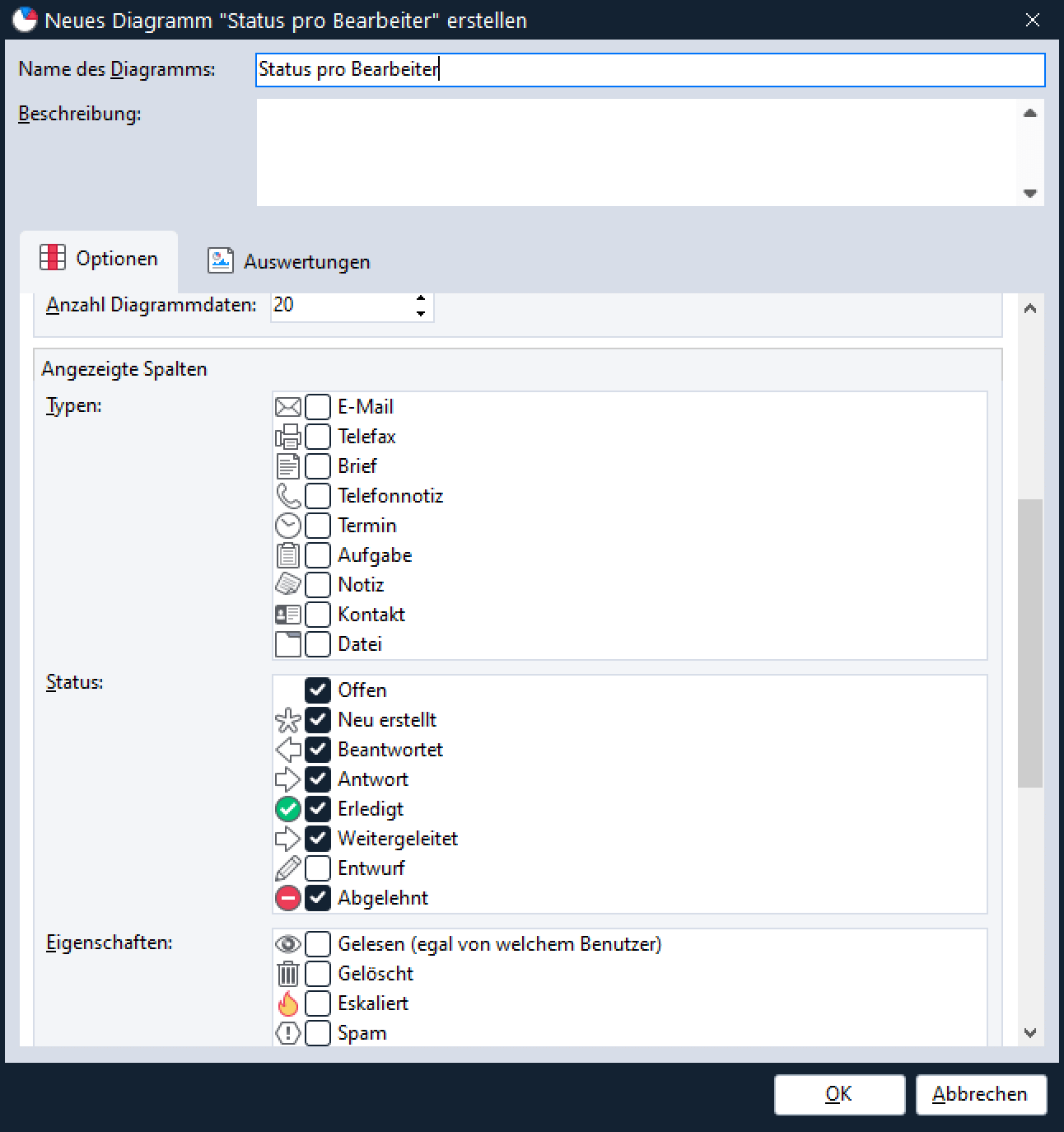
Um das Ganze zu testen, benötigen wir nun noch eine Auswertung, die unser Diagramm verwendet. Dazu speichern wir das eben erstellte Diagramm ab und legen eine neue Auswertung an bzw. öffnen eine der standardmäßig bereits angelegten Auswertungen, die das Diagramm “Status pro Bearbeiter” enthalten, z. B. “Alle > Mitarbeiterbericht“.
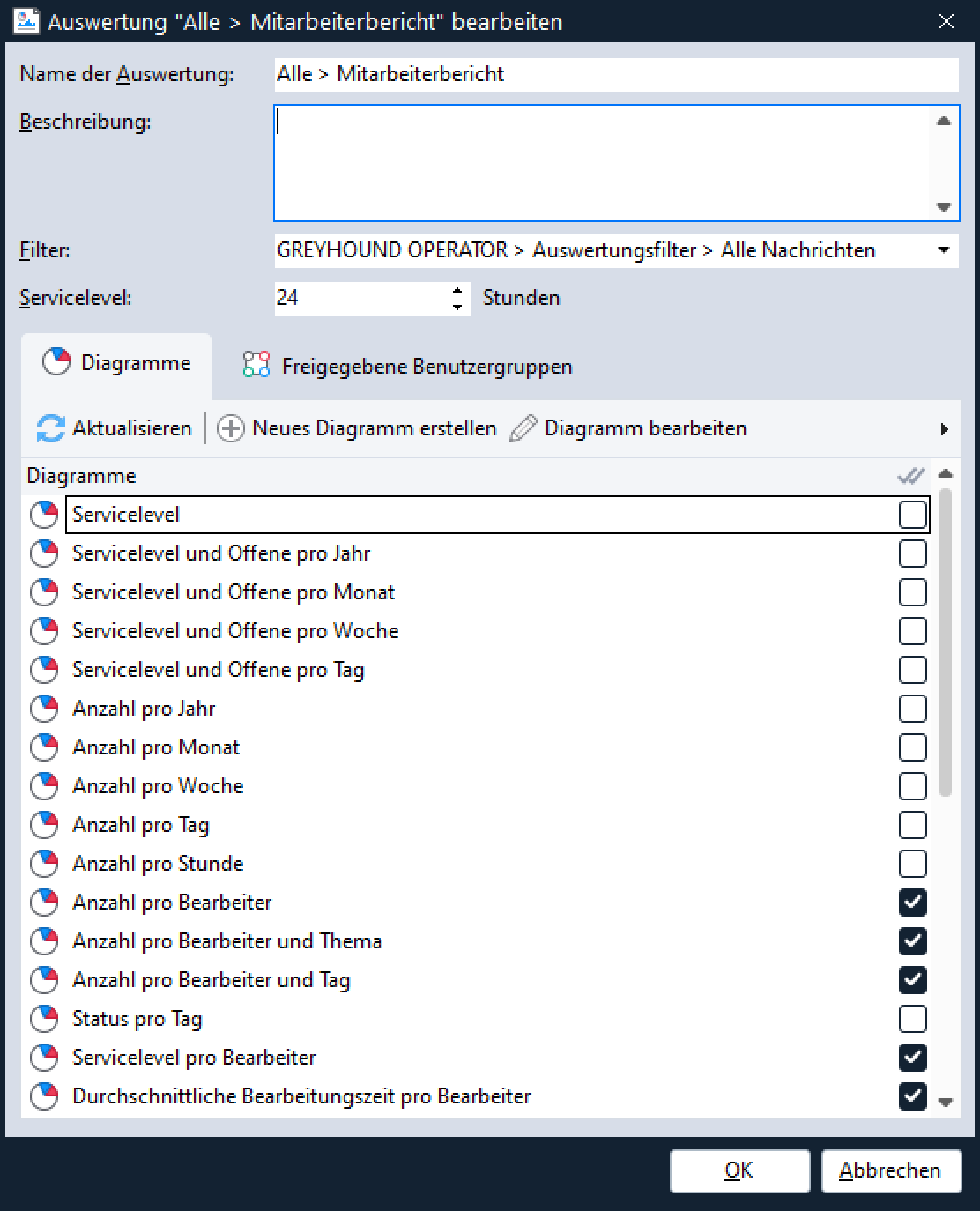
Nach einem Klick auf den Namen der Auswertung “Alle > Mitarbeiterbericht” in der Liste klickt man auf den Button “Generieren“:
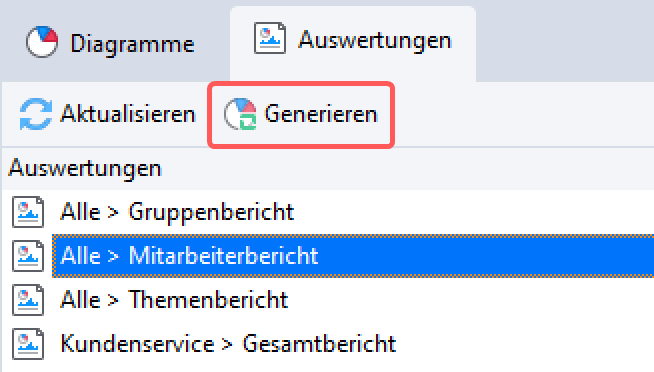
In dem nun erscheinenden Dialog kann man nochmals auf die Datenmenge Einfluss nehmen und diese zeitlich filtern:
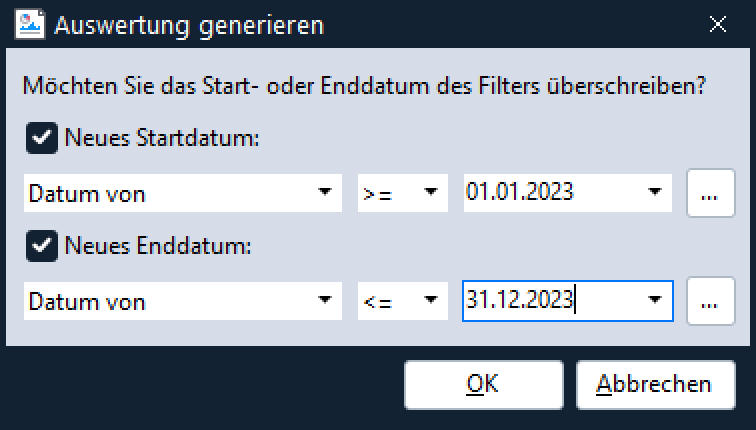
Bestätigt man mit “OK”, kann man folgende aus GREYHOUND erstellte Statistik betrachten:
Weitere Hinweise
Im Folgenden werden die möglichen Optionen für ein Diagramm genauer erläutert.
- Gruppieren nach
Ein Diagramm besteht immer mindestens aus einer Anzeigespalte und optional aus zusätzlichen Gruppierungsspalten, die hier über Checkboxen festgelegt werden können. Die Logik folgt hier dem gängigen GROUP BY Prinzip aller modernen relationalen Datenbanksysteme. Datensätze, die über den gleichen Wert in der angegebenen Gruppierungsspalte verfügen, werden zu einem Wert zusammengefasst bzw. zusammengezählt. Mehrfache Gruppierungen, z. B. nach Zeitraum und Status, clustern die anzeigten Daten somit in zwei immer wieder alternierenden Gruppen. Für alle Benutzer, die hiermit nicht vertraut sind, empfehlen wir die Literatur zu einem gängigen RDBMS. - Feld für Zeitraum
Sofern man in einem Diagramm nach Zeitraum gruppiert, hat man hier nun die Möglichkeit, genauer festzulegen, welches Datumsfeld für die zeitliche Zusammenfassung angewendet werden soll. Es stehen die vier bekannten Datumfelder “Erstellt am”, “Bearbeitet am”, “Datum von” und “Datum bis” zur Verfügung.
WICHTIG für Nachrichtenelemente: “Erstellt am” symbolisiert den Zeitpunkt des Eintreffens einer Nachricht in GREYHOUND. “Bearbeitet am” ist das letzte Änderungsdatum an dem Element, dieses kann eine beliebige manuelle oder automatische Aktion gewesen sein. “Datum von” bezieht sich auf das Datum, welches in der Nachricht (E-Mail) selbst gespeichert ist und stellt meistens das Versanddatum der Anfrage beim Kunden dar. “Datum bis” zeigt auf den Zeitpunkt, an dem die Nachricht tatsächlich im GREYHOUND beantwortet oder erledigt worden ist.
Mehr zum Thema Datumstypen - Zeitraum
Mit dieser Option wird die zeitliche Zusammenfassung genauer definiert. Sprich, man kann dem Auswertungssystem mitteilen, welche Werte als übereinstimmendes Datum gewertet werden sollen. Soll jeder Tag einzeln mit eindeutigem Datum herangezogen werden oder soll wochen-, monats- oder jahreweise gruppiert werden. Diese Einstellung wird notwendig, da eine Datum, im Gegensatz zu allen anderen einfachen Vergleichsfeldern, eine fortlaufende Größe im GREYHOUND ist und es somit sehr selten vorkommt, dass zwei Elemente exakt das gleiche Datum aufweisen und somit gruppierbar sind. Daher kann über diese Option die Granularität für die Gruppierung eines Datum / Zeitwertes festgelegt werden. - Datenreihen sortieren
Standardmäßig werden die Datenreihen (also die angezeigten Spalten) nicht sortiert, sondern die Gruppierung gibt auch die Sortierung vor. Für die Darstellung mancher Diagramme ist es allerdings sinnvoll, die Datenreihen auf- oder absteigend zu sortieren, um die visuelle Ausgabe besser beeinflussen zu können, vor allem im Zusammenhang mit der Option “Anzahl Diagrammdaten”. - Diagrammtyp
Sofern die Auswertung nicht nur tabellarisch, sondern auch grafisch erfolgen soll, kann man hier den Diagrammtyp festlegen. GREYHOUND bietet die drei klassischen Diagrammformen: Kreis-, Balken- und Liniendiagramm, wobei ersteres auch in einer 3D Form vorliegt. - Anzahl Diagrammdaten
Wenn man sich z. B. alle Nachrichten nach Gruppen aufgeteilt anzeigen lässt, kann es passieren, dass man in großen Systemen mehrere 10 – 100 Gruppen vorfindet und die Daten nun alle nach dem Gruppennamen geclustert und sortiert erscheinen. Die Datenflut ist allerdings viel zu gewaltig, um diese sinnvoll grafisch darzustellen. Deshalb sollte man die Datenreihen sortieren, in diesem Fall z. B. absteigend, und die Anzahl der Diagrammdaten begrenzen, um beispielweise nur die ersten 10 Werte grafisch anzuzeigen. Da wir absteigend sortieren bekommen wir im Folgenden nur die 10 Gruppen mit den meisten Nachrichten präsentiert, obwohl wesentlich mehr Daten in der Tabelle vorhanden sind. - Beschreibung
Im Feld Beschreibung bei Diagrammen und Auswertungen kann man optional Notizen / Kommentaren / Erklärungen hinterlegen.
Der Status bei der Filterkonfiguration
Im Zusammenhang mit Auswertungen ist von zentraler Bedeutung, was in der Filterkonfiguration zum jeweilige Status eines Elements eingestellt wird. Filter, bei denen wie im folgenden Screenshot zu sehen, ausschließlich der Haken bei. Status “Offen” gesetzt ist, berücksichtigen nur offene Elemente, die noch nicht von euch beantwortet wurden:
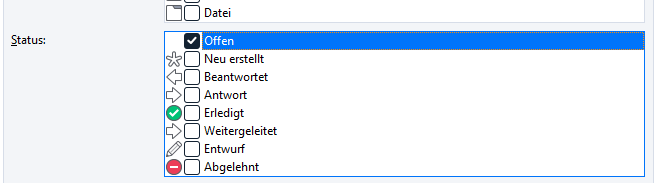
Die einzelnen Status haben folgenden Bedeutung:
 Offen = Alle eingehenden, noch nicht beantworteten oder anderweitig abgearbeiteten Elemente.
Offen = Alle eingehenden, noch nicht beantworteten oder anderweitig abgearbeiteten Elemente.
 Neu erstellt = Neue Elemente, die in GREYHOUND von einem Benutzer angelegt wurden, die keinen (direkten) Bezug auf ein vorhergehendes Element haben. Hierzu zählen z. B. E-Mails, die über die “Neu > Neue E-Mail” erstellt und versendet wird.
Neu erstellt = Neue Elemente, die in GREYHOUND von einem Benutzer angelegt wurden, die keinen (direkten) Bezug auf ein vorhergehendes Element haben. Hierzu zählen z. B. E-Mails, die über die “Neu > Neue E-Mail” erstellt und versendet wird.
 Beantwortet = Eingehende Nachrichten, die beantwortet wurden.
Beantwortet = Eingehende Nachrichten, die beantwortet wurden.
 Antwort = Ausgehende Nachrichten, die als Antwort auf ein Element erstellt wurden.
Antwort = Ausgehende Nachrichten, die als Antwort auf ein Element erstellt wurden.
 Erledigt = Elemente, die auf “erledigt” gesetzt wurden.
Erledigt = Elemente, die auf “erledigt” gesetzt wurden.
 Weitergeleitet = Elemente, die an eine (externe) Mailadresse weitergeleitet wurden.
Weitergeleitet = Elemente, die an eine (externe) Mailadresse weitergeleitet wurden.
 Entwurf = In GREYHOUND angelegte Entwürfe, z.B. einer Mail oder Notiz.
Entwurf = In GREYHOUND angelegte Entwürfe, z.B. einer Mail oder Notiz.
 Abgelehnt = Elemente, die von einer höheren Ebene (Bsp. Teamleiter) abgelehnt wurden.
Abgelehnt = Elemente, die von einer höheren Ebene (Bsp. Teamleiter) abgelehnt wurden.
Zum besseren Verständnis der einzelnen Status lohnt sich ein Blick in die Vorgangshistorie eines Elements. So wird meist schneller klar, wie die einzelnen Abläufe und der jeweilige Status sich verhalten:

Eingehende Elemente haben in GREYHOUND immer den Status “Offen“. Antwortet man auf dieses Element, erhält das eingehende Element den Status “Beantwortet“, während das ausgehende Element den Status “Antwort” rutscht.
Hinweis zum Datenschutz
Die Auswertungen in GREYHOUND sind ein mächtiges Tool, die unzählige Möglichkeiten bieten. Grundsätzlich sind die Auswertungen in GREYHOUND nicht personenbezogen – trotzdem möchten wir an dieser Stelle nochmal explizit darauf hinweisen, dass bei jeder Form von Auswertung und insb. dann, wenn Auswertungen Dritten zur Verfügung gestellt werden, auf den Schutz von (personenbezogenen) Daten achtzugeben ist und das geltende Datenschutzrecht eingehalten werden muss.